
Mikael oppsummerer språkmodeller: - Det er virkelig bare tekst!
- Jeg forklarer det på en veldig banal og irriterende måte i denne posten. Men virkelig, det er jo bare tekst, skriver Mikael Brevik om alle AI-verktøyene.

Publisert
Bruk av store språkmodeller og AI er simpelt! I alle fall i prinsippet. Alle løsninger folk prøver å forbløffe deg med hver dag på Twitter eller LinkedIn er i praksis bygd opp på samme måte–med små variasjoner. Men der-inne ligger det sjokkerende mye handlingsrom, fleksibilitet og kompleksitet.
Uten dyp forståelse kan jeg bruke Dunning-Krüger-effekten til min fordel og oppsummere store språkmodeller som GPT på en enkel måte:
Gitt sett mye forhåndstrent data og et tekst-dokument som input, tipp det neste ordet som skal inn.
Med den beskrivelsen skjønner vi fort at språkmodellene ikke automatisk sitter på noe fakta, vet noe om rett eller galt, eller har en forståelse på det som kommer ut. Samtidig er det sjokkerende hvor godt det fungerer!
I denne bloggposten skal vi se på hva som skjer når en lager egne systemer som fungerer på egen data og hvordan det egentlig bare er tekst.
Tekst, uansett
Det finnes mange forskjellige løsninger innen AI og mange forskjellige språkmodeller som fungerer på litt forskjellig måte.
I mange tilfeller, når du ser noen på Twitter eller LinkedIn snakke om alt som har skjedd innen AI siste uka (eksempelvis SalesGPT, Personal Assistant, Running ChatGPT on your own data, ChatGPT Plugins, ChatGPT 4 med søk) så baserer seg fortsatt på akkurat samme måte:
Det tar utgangspunkt i tekst og tipper neste ord. Men teksten som sendes inn er forskjellig og måten de henter informasjon på varierer.
Mange prøver å utkonkurrere hverandre i sensasjonalisme om nye AI-verktøy, selv om fleste av de bare er variasjoner av samme modellene med annen input.

Selv om det kan oppsummeres så simpelt, betyr det ikke at det ikke er mange muligheter. Jeg har begynt å se på språkmodeller som generiske protokoller eller API-er som kan interagere med naturlig språk. Men det betyr også at samme regler gjelder som med alle databaserte systemer: shit in; shit out. Siden det er så fleksibelt på input og output, gjør det også at prosesseringen, struktureringen og formuleringen av kommunikasjonen med språkmodellene er desto viktigere.
I denne bloggposten skal vi se på hva som skjer når en lager egne systemer som fungerer på egen data og hvordan det egentlig bare er tekst. Her tar jeg utgangspunkt i å forklarer fra OpenAI og Azure OpenAI API-perspektiv. Det finnes andre løsninger der ute som kan fungere på litt ulik måte, men dette er de aller mest vanlige.
Tekst, tekst, tekst
Når noen snakker om å trene opp egne modeller så er det egentlig ikke trening. Det handler bare om å samle sammen tekst som du sender inn til språkmodellen din for hver gang du vil hente ut noe. Det lagres ikke, det kan ikke gjenbrukes neste gang du skriver med ChatGPT f.eks.
Om vi ser på OpenAI API-er kan vi tenke på det som tilstandsløst. Hvordan kan ChatGPT da svare på ting du har skrevet tidligere i samtalen? Hver gang du sender inn en ny chat sender den hele komplette samtalen, så tar GPT basert på tidligere tekst å tipper neste tekst. Det er bare tekst.

“Men Mikael”, sier du kanskje, “jeg har jo hørt at nå som GPT-4 er her så er GPT 3.5 utdatert for GPT-4 har tilgang på internett. Og med GPT 4 så har den jo plugins som gjør at du kan hente informasjon fra API-er og greier. Da kan vi vel trene opp modeller selv?”.
Nei. Det er bare tekst! Men modeller som GPT 4 tillater mye mer tekst. Faktisk dobbelt så mye tekst i enkelte tilfeller, og 8 ganger så mye i andre tilfeller. Og så er det trent på mye mer data. Men det er fortsatt bare tekst.
Så hvordan kan den da hente informasjon fra internett? Den er skrevet kode som kan crawle nett og hente ut tekst og sette det inn som input til modellene. Akkurat som om du skulle gjort det selv, bare at den kan være litt smartere med søkefrasene. Og siden GPT-4 kan ta mer data inn, kan du da gjøre flere søk og samle inn mer informasjon fra nett som blir oppsummert og sendt inn som vanlig tekst til API-ene i bakkant.
Hva med annet innhold?
Men hva med systemer som Azure AI Studio hvor du kan sende inn data fra Blob Storages eller laste opp PDF-er? Betyr det at Azure OpenAI har støtte for å lese og trene seg opp på dine PDF-er? Nei, da! Det er selvfølgelig bare tekst.
Men Microsoft har her laget system som samler inn PDF-er, leser PDF-er, lagrer de som tekst, og når du da skriver en chat i Azure AI Studio sender den inn relevant tekst fra PDF-en først, uten at du ser det.
Nå er jeg lei retoriske spørsmål så jeg gjør det enkelt: Det er akkurat samme hvor det integreres mot et API-lag. Det er bare tekst som sendes inn som kontekst til samtalen.
Det vil si at uansett om du henter informasjon fra nett, PDF-er eller API-er så ser det i praksis slik ut: Selv om du sender inn en melding er det som sendes inn prefikset av en kontekst som er samlet inn av datasystemer.

Om du bruker Azure AI Studio og trent på dine PDF-er og du skriver i en chat:
"List opp 3 av våre største kunder"
Vil det i realiteten overføres mye mer til OpenAI API-ene. F.eks:
"Informasjon tilgjengelig: [Tekst hentet fra PDF her]
Spørsmål: List opp 3 av våre største kunder"
Med andre ord: Det er virkelig bare tekst.
Men du har kanskje sett eller hørt snakk om embeddings og vektorer for input til språkmodeller. Så hvordan passer det inn? La oss se hva det egentlig er.
Embeddings, vektorer og cosinus er bare tall
Det er viktig å vite at språkmodellene har begrenset støtte for hvor mye tekst de kan få inn. Jeg sa tidligere at GPT 4 har minst dobbelt så mye som GPT 3.5 (selv om det nå finnes noen GPT 3.5 modeller med støtte for mer input). For GPT 3.5 modeller betyr det at det kan sendes inn typisk 4000 tokens, eller tilsvarende 4–5 A4-sider med tekst.
Men det er enda mer begrensninger her, for denne grensen gjelder for data som sendes INN og UT. Det vil si at det i realiteten er veldig lite som kan sendes inn som kontekst. Her kommer embeddings inn, det er en måte å hente mest mulig relevant kontekst slik at vi slipper å sende inn alt vi har av data hver gang.
Vektordatabaser kan hente ut lik data basert på distanse mellom vektorer.
For å hente ut relevant informasjon blir tekst og kontekst lagret i egne databaser hvor teksten er representert av flyt-tall, eller vektorer om du vil. Om en lager embeddings via OpenAI sine API-er, vil du få returnert en vektor med all tekst representert som tall. Dette kan så lagres i en vektor-database. Når en en da skal hente ut innhold igjen basert på en søketekst blir også den søketeksten gjort om til vektorer.
Det er viktig å vite at språkmodellene har begrenset støtte for hvor mye tekst de kan få inn.
For å finne tekst i databasen som er relevant sjekkes det opp med hjelp av gode gamle cosinus, på hva slags tekst som har minst distanse fra søketekst til det som ligger i databasen fra før. Den kan hente ut prioritert liste med søkeresultat. Fra der kan vi så gjøre det om til tekst igjen og sende det som vanlig tekst rett inn som kontekst, slik som beskrevet i forrige kapittel. Men det ender altså bare opp som vanlig tekst.
Embeddings og vektordatabaser har altså egentlig ikke noe med AI og gjøre, men det er for å prøve å hente ut mest mulig relevant kontekst å sende inn som ren tekst til en språkmodell. Det kan selvfølgelig også brukes i andre sammenhenger.
“Prompt engineering” er bare tekst
Prompt engineering har du kanskje hørt mye snakk om. Et tilsynelatende helt nytt fagfelt hvor det er dedikerte mennesker som temmer språkmodeller som om de skulle vært slangetemmere med ocarina fra Zelda.
Jeg skal ikke holde deg på pinebenken her; det er også bare tekst.
Men om vi ser på språkmodeller som et API i naturlig språk ser en kanskje at kompleksiteten kan vokse. For når det er så mye fleksibilitet i protokollen betyr det at det er veldig mye opp til deg som skal skrive en spørring opp mot modellene. Hvordan du strukturer, formulerer og prioriterer prompts.

Språkmodeller er ikke mennesker og du trenger ikke snakke til de som mennesker. Faktisk vil du kunne få mye bedre resultater dersom du ikke skriver til språkmodellene som om det skulle vært din brevvenn som du møtte på Rhodos i 2006.
Dette er prompt engineering. Kompetansen av å skrive prompts og input på en slik måte at du får konsis og korrekt resultat fra språkmodeller. Med så fleksible protokoller, kreves det mer av oss som konsumenter. Men mulighetene blir også mye større.
Prompt engineering kan brukes til å lage forhåndsdefinerte templater av tekst som tar inn informasjon og setter det inn i nøye dedikerte steder. Jeg er ingen god prompt engineer, i den grad noen kan være det, men eksempel på en prompt kunne ha vært noe slik:
Rolle: Du er en kul samtalepartner som kun skal snakke om
turen du og brukeren hadde på Rhodos i 2006.
Tidligere samtaler via brev er finnes mellom <brev> og </brev>.
Spørsmål kommer innenfor <spørsmål> </spørsmål>.
Du skal kun svare basert på tidligere innhold og samtaler.
<brev>
Fra: Bruker
Til: Brevvenn
Hei! Takk for sist. Her i Møre og Romsdal er det kaldt.
</brev>
<brev>
Fra: Brevvenn
Til: Bruker
Ja, her i Oslo er det kjedelig nå også. Vi har den ene dagen med regn som vi har i året.
</brev>
<spørsmål>
{{Innsendt spørsmål fra system}}
</spørsmål>Systemer for å skrape sammen tekst
Siden modellen i utgangspunktet er så simpel, legger det mer ansvar på oss for behandling av input den får tilgang på. Det betyr å hente rett informasjon og vaske den til å kun ha det relevante.
Jeg liker å skille input inn i 2 kategorier: kontekst og prompt. Kontekst er all den bakgrunnen og teksten språkmodellene skal ta utgangspunkt i. Prompt er som vi så i forrige avsnitt, inputen som sier noe om hva du forventer som resultat. Videre så vi i forrige avsnitt hvor viktig prompt er, men nå skal vi se på hvor viktig kontekst er.
Det finnes ulike etablerte verktøy for å behandle data og ta det hele veien fra “generell data” til “kontekst for språkmodeller”. Du har kanskje hørt om verktøy som LangChain. Dette er sammensydd kode for å gå fra ren data, til input på språkmodeller, og gradvis forbedring av data. Det er alt kommet mange patterns og arkitekturer for å støtte opp prosessen med å gå fra data til kontekst.
Vi har alt sett på hvordan embeddings og vektor-databaser kan brukes til å lagre og søke i data som kan sendes inn som kontekst. Men for at det skal havne i vektor-databaser må vi ha datastrømmer fra de kildene som er relevante. De kildene kan være hva som helst. API-er, PDF-er, Word-dokumenter, BigQuery, PowerBI, andre nettsider, osv. Å gå fra rå data til embeddings krever patterns og systemer. Dette må i mange tilfeller implementeres spesifikt for akkurat dine bruksområder, selv om det finnes biblioteker til å hjelpe deg litt.
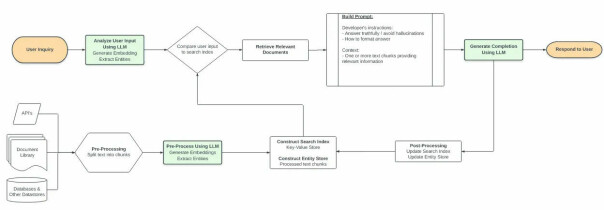
Men det viser seg også at vi kan bruke språkmodeller rekursivt. For hva skjer f.eks når konteksten blir for lang og vi bruker opp antall tilgjengelige ord vi kan sende inn? Jo, vi kan jo bruke det fleksible API-et vi har i språkmodeller til å be språkmodellene korte ned men fremdeles ivareta informasjonen som er i konteksten vår. Så kan vi igjen lagre den konteksten i mindre format og da bruke den som kontekst inn mot språkmodellene. Dette kan vi bruke på mange forskjellige måter, f.eks med å få hjelp til formulere prompts, trekke ut sentral informasjon, generere ny kontekst osv.
Vi kan ikke bare sende inn alt mulig som kontekst til språkmodeller. Husk at det er en språkmodell og tegn er jo egentlig bare tegn. Så om vi sender inn mye irrelevant tegn via JSON-struktur eller bare API-data rått, vil det redusere sjansene for å få fornuftig svar ut. Vi må prosessere data til å sendes inn på en slik måte som gir språkmodeller best mulig forutsetning for å lykkes.

Konklusjon
Jeg forklarer det på en veldig banal og irriterende måte i denne posten. Men virkelig, det er jo bare tekst. Men samtidig er det så fleksibelt, så kraftig, og så usannsynlig imponerende.
Men ettersom bruken av det på overflaten er så simpelt, betyr det at det krever mer av oss som skal bruke det på ulike måter. Vi må designe systemer som henter inn rett type data, strukturerer det på rett mulig måte, lagrer det på en slik måte at det kan sendes inn, og spør på rett måte for å få god informasjon ut.
Vi må ha rutiner til å hente inn informasjon og prosessere det. Vi må ha kunnskap om hva vi ønsker å ha ut av systemet og legge til rette for at konteksten som skal sendes inn kan hentes ut fra datalag på en effektiv og presis måte. Det finnes ulike patterns og arkitekturer for å få det til, men det må tilpasses ut i fra hva hva vi ønsker å gjøre og hvilket resultat vi vil oppnå.
Ja, på overflaten er det bare naturlig språk og tekst, men ser vi litt lengre, ser vi at det er verdens mest avanserte og fleksible API. Og som alltid: shit in; shit out. Så jobb for mindre shit in.
Foretrekk oss i Google Discover
Ved å legge oss til som foretrukket kilde i Google vil du blant annet få opp flere av sakene våre i Google Discover. Tusen takk for støtten!



































