
Advarer mot å la brukerne selv chatte med AI: - De kan ikke prompt engineering
- Ved å inkludere forhåndsdefinerte prompter kan brukere få en enklere start på interaksjonen med språkmodellene, tipser Mathilde Haukø Haugum.

Publisert
Den siste tiden har det vært mye oppmerksomhet rundt hvordan store språkmodeller (LLM-er) som GPT kan integreres i applikasjoner for å skape verdi for brukerne. Et eksempel er Khan Academy, som har brukt GPT-4 til å lage en assistent du kan chatte med for å få personlig veiledning i læringsprosessen.
For å utvikle denne løsningen bruker de mye ressurser på å vurdere kvaliteten til responsen som produseres av språkmodellen. Blant annet bruker de menneskelige testere til å gi tilbakemelding på når modellen produserer feilaktige svar. Få bedrifter har muligheten til å bruke så mye ressurser på å utvikle og trene opp en LLM. For disse bedriftene er det viktigere at det blir utformet gode prompter som kan gi riktige svar fra begynnelsen av.
Derfor er det viktig at vi bygger kompetanse innenfor prompt engineering. Slik kompetansebygging er en del av Variants AI-strategi, som beskriver vårt ønske om å skaffe praktisk erfaring innen bruken av kunstig intelligens, slik som LLM-er, for å skape verdi for både oss og kundene våre.
Som en del av denne strategien har vi gjennomført et prosjekt der vi har utviklet en applikasjon som bruker Spark API-et til Volue.
Derfor vil ikke en chat alltid være den mest hensiktsmessige tilnærmingen for å utnytte de potensielle fordelene ved de kraftige språkmodellene.
Vanskelig fagområde
Applikasjonen henter inn strømprisdata fra dette API-et og bruker denne dataen til å generere velutformede råd om optimal strømbruk.
I løpet av prosjektet har vi identifisert nyttige tips for å skrive gode prompter. Samtidig har vi observert utfordringen ved å kun tilby interaksjon med språkmodellen via et chat-grensesnitt.
Prompt engineering er et relativt nytt fagområde, så de fleste brukerne mangler evnen til å designe gode prompter. Hvis chat-interaksjonen ikke er testet og vurdert i like stor grad som løsningen til Khan Academy, vil brukerne ofte oppleve at de får responser som ikke svarer på deres spørsmål eller gir feil informasjon.
Derfor vil ikke en chat alltid være den mest hensiktsmessige tilnærmingen for å utnytte de potensielle fordelene ved de kraftige språkmodellene. I dette blogginnlegget ønsker vi å dele våre erfaringer med hvordan forhåndsdefinerte prompter kan bidra til å skape bedre brukeropplevelser og spre kunnskap om utformingen av gode prompter.

Hvorfor er det vanskelig å skrive gode prompter?
Prosessen med å utforme gode prompter kalles prompt engineering, og det spiller en avgjørende rolle i å programmere en LLM på en effektiv måte. Dersom språkmodellen mottar en forespørsel som ikke følger noen taktikker for prompt engineering, er det større sannsynlighet for at den gir feil informasjon eller svarer på noe helt annet, fordi den ikke forstår hva du ønsker.
For eksempel i vårt prosjekt når modellen mottok prompten “Når er det billigst å bruke strøm i dag?” ville den ofte foreslå både feil tidspunkt og feil dag.
For å bli bedre på å skrive prompter til GPT, kan du lese dokumentasjonen til OpenAI som beskriver ulike taktikker som kan gjøre at du får bedre responser. En av disse taktikkene innebærer å bruke skilletegn, som trippel anførselstegn (“””), for å tydelig skille konteksten fra resten av prompten. Dermed blir det lettere for modellen å forstå hvilken kontekst den skal bruke for å svare på spørsmålet ditt.
En annen nyttig taktikk er å dele komplekse instruksjoner opp i flere steg som er lettere å følge for modellen. I vårt prosjekt brukte vi seksjonstittelen “Strømdata” for å referere til strømprisdataen fra Spark API-et, og vi brukte stegvis oppdeling for å finne det billigste tidspunktet å bruke strøm i dag. Ved å implementere disse taktikkene ble det lettere for modellen å forstå hva vi ønsket og dermed produsere riktig svar.
messages=[
{
"role" = "user",
"content" = "Strømdata: " + f"{spark_data}",
},
{
"role": "user",
"content": "Følg disse stegene: Steg 1: Se på det første elementet"
"i strømdataen for å bestemme hvilken dag det er i dag."
"Steg 2: Finn alle prisene for denne dagen du fant i steg 1."
"Steg 3: Finn den billigste prisen blant prisene fra steg 2."
"Svar med kun en setning",
}
]En av utfordringene med prompt engineering er at det ikke finnes en fasit på den beste tilnærmingen. Resultatene du oppnår ved å bruke ulike taktikker vil variere avhengig av flere faktorer. Noen av faktorene som kan ha stor betydning, er hvilken GPT-modell du bruker og formatet til dataen du gir til modellen.
Derfor vil det kreve en del prøving og feiling for å utforme prompter som fungerer godt for din bruk. For hver endring som gjøres i prompten, må du også gjennomføre systematisk testing for å avgjøre om endringene gjorde prompten bedre eller ikke.
Hvis du ønsker å forbedre dine ferdigheter i å skrive gode prompter, kan du sjekke ut vårt blogginnlegg som gir noen nyttige tips.
Dermed blir det utfordrende for brukerne å skrive en prompt.
Utfordringer med chat-grensesnittet
Prompt engineering er et relativt nytt og lite kjent fagområde, noe som gjør at de fleste brukere ikke har kjennskap til hvordan utformingen av prompten kan påvirke kvaliteten på responsen de mottar. Når brukere sender sine forespørsler gjennom et chat-grensesnitt, vil de derfor ofte ikke benytte seg av taktikker for prompt engineering. Selv om noen brukere vet hvordan de kan skrive gode prompter, vil de sjelden være kjent med hvilke spesifikke taktikker utviklerne har brukt.
For eksempel vil de ikke vite om utviklerne har brukt skilletegn, og i så fall hvilke skilletegn som er benyttet. Dermed blir det utfordrende for brukerne å skrive en prompt som bruker skilletegn for å begrense hvilken kontekst modellen bruker til å generere responsen.
I systemmeldingen kan det oppgis at dataen innenfor skilletegnene skal benyttes til å svare på brukernes meldinger. Da er det viktig at dataen som plasseres innenfor skilletegnene kun inneholder informasjon som det er akseptabelt at brukerne har full tilgang til.
For eksempel bør du unngå å avsløre detaljer om strukturen til JSON-objekter eller annen sensitiv informasjon som ikke skal eksponeres.

Ustabil løsning
I tillegg til å bruke skilletegn for å referere til konteksten på en effektiv måte, er beskrivelsen av den ønskede handlingen som skal utføres på konteksten også avgjørende for kvaliteten til responsen.
Som nevnt tidligere oppnådde vi bedre respons når vi brukte skilletegn og en stegvis tilnærming når vi ønsket å finne det billigste tidspunktet å bruke strøm i dag. De fleste brukere er ikke kjent med disse taktikkene og vil i stedet skrive prompter som “Når bør jeg bruke strøm i dag?”.
For at det skal bli lettere for modellen å forstå hva brukeren ønsker, er det bedre om prompten vi har skrevet utløses når brukeren skriver denne prompten i chat-feltet. For å oppnå dette kan man implementere betinget utførelse av handlinger i systemmeldingen, slik at når applikasjonen mottar en spesifikk forespørsel fra bruker, vil en tilhørende prompt vi har laget bli utført.
Utfordringen med denne tilnærmingen er at systemmeldingen blir mer kompleks, noe som kan føre til at deler av meldingen blir ignorert dersom du bruker GPT-3.5-turbo modellen.
I vårt prosjekt brukte vi denne språkmodellen og opplevde at den kunne utføre en handling selv om betingelsen ikke var oppfylt. Dermed fikk vi en mer ustabil løsning som ikke la til rette for gode brukeropplevelser.
Å trykke på en knapp med en ferdig formulert forespørsel kan oppleves som mindre utfordrende.
Hvorfor inkludere forhåndsdefinerte prompter?
Brukere som har mindre erfaring med å skrive prompter, kan være usikre på hvordan de skal formulere promptene. I slike tilfeller kan forhåndsdefinerte prompter være til stor hjelp, da de gir brukerne en enklere start på interaksjonen med språkmodellen.
Å trykke på en knapp med en ferdig formulert forespørsel kan oppleves som mindre utfordrende enn å skrive en egen forespørsel i et chat-felt. Disse knappene kan inneholde forenklede og komplette setninger og utløse tilhørende prompter som du har utformet ved å benytte taktikker for prompt engineering.
I vårt prosjekt med Spark API-et inkluderte vi for eksempel en knapp som kunne brukes til å finne det billigste tidspunktet å bruke strøm på søndager. Når brukeren trykket på denne knappen, ble følgende prompt sendt til språkmodellen:
messages=[
{
"role": "user",
"content": "Bruk strømdataen og finn alle priser for søndagen."
"Sammenlign prisene og identifiser elementet med lavest pris."
"Svar med kun en setning som oppgir dag, tidspunkt og pris",
}
]Denne prompten bruker seksjonstittelen strømdata for å referere til konteksten. I tillegg inneholder prompten flere detaljer som er nyttige for å lage klare instruksjoner som er enklere for modellen å forstå.
Hvis du ønsker å gi brukeren mer frihet til å bestemme innholdet i prompten selv, kan du inkludere et input-felt der de kan legge inn nøkkelord som blir satt inn i prompten du har definert. Dermed kan du implementere prompter som drar nytte av beste-praksis innen prompt engineering, samtidig som brukeren kan påvirke retningen til prompten uten å måtte tenke på formuleringen.

En kombinasjon
Hvis man ønsker å gi brukere muligheten til å skrive inn prompter selv, kan det være gunstig å tilby en kombinasjon av et chat-grensesnitt og forhåndsdefinerte prompter.
I slike tilfeller bør du vise frem de forhåndsdefinerte promptene, da de kan gi verdifull innsikt om hvordan brukerne bør utforme sine egne prompter for å få bedre responser.
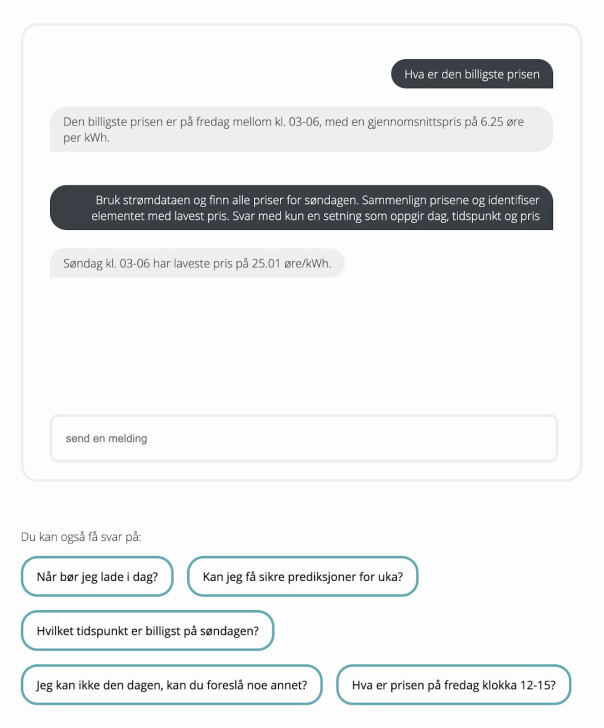
I vårt prosjekt valgte vi å vise frem den forhåndsdefinerte prompten når brukeren trykket på knappen “Hvilket tidspunkt er billigst på søndagen?”. Dermed kunne brukerne blant annet se at vi refererte til dataen ved å bruke ordet “strømdataen”, og de kunne dermed bruke denne tilnærmingen i videre interaksjon med språkmodellen.
Dersom du viser frem formuleringen av promptene dine kan du bidra til å spre kunnskap om prompt engineering, samtidig som du kan gjøre det enklere for brukerne dine å formulere gode prompter.
Selv om chat-grensesnitt er populære i LLM-applikasjoner, er det ikke alltid den beste måten å la brukere interagere med språkmodeller. Prompt engineering er avgjørende for å skrive gode prompter, men det er et relativt nytt fagområde som få brukere har kjennskap til.
Ved å inkludere forhåndsdefinerte prompter kan brukere få en enklere start på interaksjonen med språkmodellene og dermed dra nytte av beste praksis innen prompt engineering uten å måtte ha kunnskap til det selv. En kombinasjon av chat-grensesnitt og forhåndsdefinerte prompter, som demonstrerer brukte teknikker i promptene, kan bidra til å spre kunnskap om prompt engineering.
Dermed kan brukerne bli flinkere til å skrive gode prompter selv, noe som igjen kan føre til bedre resultater og dermed mer tilfredsstillende brukeropplevelser.

Foretrekk oss i Google Discover
Ved å legge oss til som foretrukket kilde i Google vil du blant annet få opp flere av sakene våre i Google Discover. Tusen takk for støtten!

































