
Integrerte appen med GPT-4: - Brukte mest tid på prompt engineering
- Integrasjonen er relativt lettvint, men å få modellen til å fungere som man vil kan være utfordrende,
forteller utvikler Brynjard Buvarp Misvær i Honk.

Publisert
Honk er en markedsplass for bilabonnement i Norge og Sverige, eid av Schibsted. Målet er å hjelpe brukere raskt og enkelt å finne og bestille det bilabonnementet som passer for dem, når det kanskje ikke frister å kjøpe eller lease.
Som utvikler i Honk har vi muligheten til å bygge ting raskt og iterere. Tjenesten har sitt utspring fra FINN.no, men består av et relativt lite og autonomt team.
Med bakgrunn i hypen for generativ AI som har vært den siste tiden, bestemte vi oss for å ha en “AI hackweek” for noen måneder siden. Formålet med dette var todelt:
- Se om vi kunne bruke generativ maskinlæring for å lage nye features med formål om å øke konvertering på plattformen.
- Lære mer om teknologien som er overalt om dagen, og ha det gøy (naturligvis).
Modellene konstruerer en del vissvass, som de tilsynelatende genererer på helt egen hånd.
OpenAIs GPT-API
Vi endte opp med å bruke API-et til OpenAI for GPT-modellene (modellene bak ChatGPT), men andre modeller, som Midjourney, ble også vurdert i de innledende diskusjonene.
I tiden før dette prosjektet skulle gå av stabelen, hadde samtlige på teamet brukt ChatGPT en stund, både for generelle spørsmål, men mer spesifikt for programmeringsrelaterte ting.

Etter å ha blitt kjent med ChatGPT og GPT-apiet, kom vi frem til noen potensielle utfordringer:
- Formatet på output er ofte ustabilt. Dette er en utfordring hvis du skal få et program til å tyde output fra modellen, såfremt man vil bevege seg ned en dyster vei preget av regex-uttrykk jeg ikke tør tenke på etter mørkets frembrudd.
- GPT-modellene er basert på data frem til september 2021. Dette kan potensielt føre til at de kommer med foreldet informasjon eller mangler kunnskap om nyere bilmodeller.
- Modellene konstruerer en del vissvass, som de tilsynelatende genererer på helt egen hånd.
- Støtende innhold. Det finnes flust av eksempler hvor man har fått ChatGPT til å produsere innhold man ikke ønsker å ha på en markedsplass.
API-et for GPT er ganske lettvint å jobbe med. Man sender enkelt og greit et JSON-objekt med en melding og en auth-header, og svosj! så får du et svar.
Samtidig kan man også definere rollen beskjeden har, f.eks som user (sluttbruker, det DU er når du bruker ChatGPT), eller system, som er en type meta-meldinger du kan sende til modellen for å legge føringer for hvordan den skal oppføre seg, eksempelvis “you are an all-knowing car-salesperson…”.
Så hvordan jobbet vi rundt disse utfordringene for å lage noe vi mente hadde verdi? Og hva fikk vi lagd på en uke?
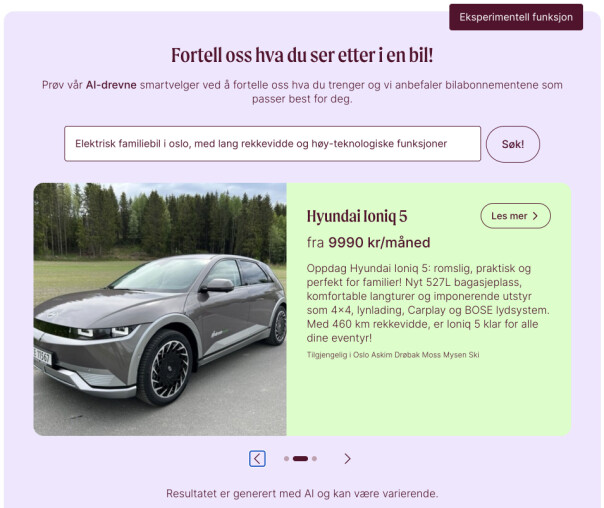
Vehicle recommendation tool
Denne funksjonen kan kanskje best oppsummeres som en GPT-powered søkemotor:
Brukeren søker etter det de ønsker i en bil, vi tar denne søketeksten, klasker den sammen med en prompt vi selv har definert, slenger med noe data om bilene vi har i sortimentet, og sender det til GPT. GPT returnerer så de 3 bilene den mener passer best gitt søketeksten, og det er det vi presenterer for brukeren.
Det første jeg vil nevne med denne funksjonen som vi synes er litt fiffig, er at brukeren aldri ser output fra GPT. Det er derfor ikke mulig for brukeren å få servert upassende eller støtende innhold. Vi har allerede sett et godt antall forsøk på å få funksjonen til å gjøre ting vi ikke ønsker at den skal gjøre - i verste tilfelle får du foreslått noen biler som kanskje ikke står helt til forventningene, eller at funksjonen viser en feilmelding.
Men det er viktig å ikke ha altfor høye forhåpninger til dette heller. Det er tross alt snakk om en språkmodell som til syvende og sist er god på å predikere en serie med tokens etter hverandre. Som det gamle proverbet sier - Shit in, shit out.

Justere prompter
Den største utfordringen fra et teknisk perspektiv, var å få modellen til å returnere 3 biler på et konsekvent format.
Etter å ha brukt nesten en uke på å skru og finjustere prompten vi sender med brukerteksten til GPT, kan jeg ærlig talt ikke fortelle dere akkurat hva som gjorde at vi gikk fra noe som ikke fungerte, til noe som fungerer ganske greit. Men, vi har en teori om at dersom du gir tydelig nok instrukser til modellen, og man bruker GPT-4 kontra GPT-3, så vil den oppføre seg relativt stabilt. Prompt-engineering er enn så lenge ikke en eksakt vitenskap.
Et annet problem vi måtte løse var å gi GPT en slags kontekst for å forstå at den kun skulle vurdere bilene vi har i vårt sortiment. Løsningen for oss ble derfor å sende en liste med data om alle bilene i sortimentet sammen med meldingen fra brukeren, for å si til modellen at “gitt DISSE bilene, velg de tre mest passende...”.
Løsningen: Be GPT innta rollen som bilselger.
Begrensa API
Ganske lurt? Tja, da støtte vi på en annen utfordring, nemlig å få sendt all dataen vi ønsket til GPT.
OpenAI begrenser APIene sine ved å sette en grense på hvor mange tokens en interaksjon (altså spørsmål og svar i samme kontekst) kan ha. I skrivende stund finnes GPT-4 med en 8K og 32K versjon, som gir deg en grense på henholdsvis 8 000 og 32 000 tokens totalt. Når vi jobbet med dette tidligere i vår, hadde vi kun tilgang til 8K-versjonen av GPT-4. Det vil si at vi ikke kunne sende store dataobjekter med bil-data (spesielt når det er over 100 ulike av dem). Løsningen på dette var å bruke en slags fattigmanns-encoding for å komprimere dataen, samtidig som at vi måtte ta noen valg på hvilke data-punkter vi ville sende. Drivstoff-type, eller pris er eksempelvis noe man gjerne vil prioritere å få med.
- Men hva med dataen GPT er trent på? Du sa den ikke var nyere enn September 2021 - hvordan påvirket det denne løsningen?!
Nei, det har du, den observante leser, helt rett i. Som nevnt tidligere sender vi noe data til GPT om hver enkelt bil. Vi tenkte at GPT har noe grunnlag for å si hva en Hyundai Ioniq er, selv om den ikke kjenner spesifikt til årets modell, og vi opplevde simpelthen at det fungerte godt. Ikke en eksakt vitenskap, indeed.
Teksten du ser i det grønne feltet i bildet med søkeresultatet er også interessant: Vi hadde en utfordring hvor vi ville presentere bilene på en innbydende måte, uten å kun ramse opp harde tall og kalde fakta om bilmodellen.
Løsningen: Be GPT innta rollen som bilselger, og be den lage en kortfattet pitch til hver bil. Det fungerte egentlig ganske godt, og det leder meg inn på neste feature vi jobbet med.
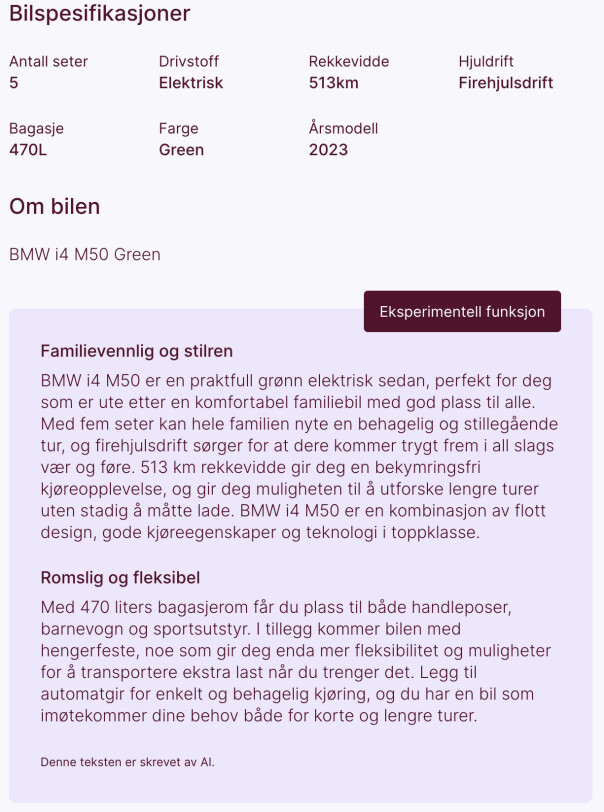
Fit descriptions
Vi ville se om vi kunne tilføre noe nytt til annonsesidene til hver enkelt bil.
I motsetningen til søkefunksjonen, hadde vi her muligheten til å sende GPT alle datapunktene om hver bil, da dette ikke er en feature man interagerer med på samme måte som en søkefunksjon.
Her ga vi GPT-4 beskjed om å konstruere to paragrafer som sier noe om hvem bilen passer for, og ga den streng beskjed om å kun forholde seg til dataen vi sendte, og ikke gjøre noen antagelser utover dette. Dette var nøkkelen til å få dette til å fungere - vi opplevde at modellen genererer overraskende lite illusjoner, og at beskrivelsene ofte fungerte relativt godt.
Igjen har vi også en trygghet om at brukeren ikke selv interagerer med GPT gjennom vårt system, og unngår derfor upassende innhold på plattformen. Det er også verdt å nevne at GPT APIet kan ta imot et parameter for temperatur. Dette parameteret har en verdi mellom 0 og 2, hvor 0 gjør outputen mer deterministisk, og 2 vil gjøre at modellen bortimot responderer på et språk hittil ukjent for mennesker.
Her er det også muligheter for å eksperimentere, men vi fant ut av at en lavere temperatur gir et bedre grunnlag for konsekvent output.

Så, hva lærte vi?
For vår del brukte vi det meste av tiden på prompt engineering. Integrasjonen med modellen er relativt lettvint, men å få modellen til å konsekvent fungere som man vil (spesielt hvis man må forholde seg til begrensninger med antall tokens) kan være utfordrende.
Det er også utfordrende å teste ulike prompts. Vi hadde ikke tid til å sette opp et skikkelig validerings-rammeverk for å sjekke hvilke prompts som fungerte bedre enn andre, og måtte gå litt etter hva vi selv opplevde som best.
En slik sprint er utrolig gøy! Og det er veldig bra for team-spiriten. Vi opplevde også at det var en veldig effektiv måte å få hele teamet opp på et felles kunnskapsnivå på et tema som uten tvil kommer til å prege arbeidshverdagen fremover.
Kanskje det også gjør oss litt bedre rustet til å takle tidspunktet når/hvis robotene kommer bankende på døra og skal ta jobbene våre også?

Foretrekk oss i Google Discover
Ved å legge oss til som foretrukket kilde i Google vil du blant annet få opp flere av sakene våre i Google Discover. Tusen takk for støtten!































