
Sånn takler Geodata 100.000 forespørsler i minuttet med Kubernetes
Kartgiganten om drift, hosting, hjemmelagde løsninger og patching av Log4j: - Det ble en samlende øvelse.

Publisert
Trenger du kart, geografiske data, flybilder eller hva som helst som har noe med kart å gjøre, er det gode sjanser for at du bør snakke med norske Geodata.
Med 180 ansatte i Trondheim, Stavanger og Oslo er de markedsledende på såkalte geografiske informasjonssystemer - GIS.
Og med de mange kundene og tjenestene, følger mye bruk og alle de utfordringer det gir.
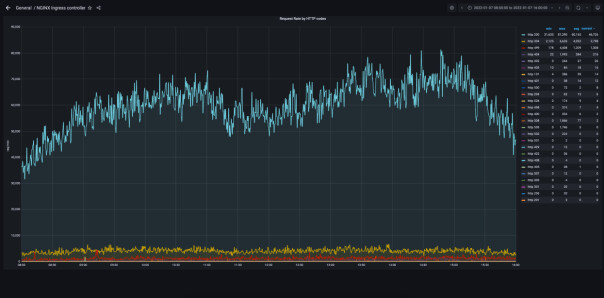
- I løpet av en arbeidsdag ligger gjennomsnittet på antall requests per minutt på 70.000. Hoveddelen av dette er kartfliser til bakgrunnskartene våre, forteller leder Pål Kristensen og utvikler Steffen Pøhner Henriksen i Geodatas Plattform Devops-avdeling.
- I perioder med mye trafikk, kan vi se over 100.000 requests per minutt. Dette ser vi ved hendelser som skredet ved Gjerdrum, når det er interesse for preppestatus i skiløypene til Skiforeningen på en utfartsdag, eller andre ekstraordinære hendelser.
Så hvordan jobber Geodata med drift og hosting av alle tjenestene sine? Vi tok en prat med Henriksen og Kristensen til spalta vår Slik drifter vi.

Hva er det mest unike med driftsbehovene deres? ✌
Vi drifter en plattform for mange ulike typer kunder med forskjellige behov. Derfor må vi kunne støtte opp under mange teknologier på både database-, backend- og frontendnivå.
Plattformen skal være enkel å bruke for våre prosjektteam med ulike krav fra kunden og ulik kompetanse. Det er derfor viktig at plattformen er allsidig, brukervennlig og tilbyr et vidt spekter av verktøy slik at vi kan møte kundens behov på best mulig måte.
Hvert prosjektteam jobber autonomt og uten å forholde seg til underliggende skyleverandører. Vi har bygget opp en Cloud Native-plattform som gjør at konsulentene kan gjøre jobben sin med kjente verktøy, men uten å ha inngående kunnskap om en spesiell skyplattform.
Via Kubernetes-objekter kan konsulentene opprette og forvalte ressurser for lagring, databaser, karttjenester og webapplikasjoner etter behov. Hvert prosjekt er adskilt fra hverandre, men deler samtidig de underliggende hardware-ressursene for å utnytte potensialet i skyen.
Sett i ettertid, og med den innsikten vi har nå etter å ha driftet Kubernetes og løsninger på Kubernetes i seks år, er det lett å tenke at ikke alle valgene vi tok innlednigsvis nødvendigvis var like gjennomtenkte.
Hvor hostes og driftes det dere bygger i dag? 📦
Plattformen vår er bygget på et Cloud Native-prinsipp som vil si at vi forsøker å ikke knytte oss for sterkt til en skyleverandør.
Vi hoster i dag plattformen vår på AWS, men har også noe på Azure der det behov for det. Vi begynte med AWS tilbake i 2009, og da var det naturlig å starte reisen vår med Kubernetes på AWS. Siden 2009 har vi gjennomgått mange transformasjoner av plattformen vår. Med tiden har vi bygget opp en solid kompetanse på AWS og det har vært naturlig fortsette der.
Vi utelukker ikke at vi flytter plattformen til en annen skyleverandør som ligger nærmere våre kunder i Norge i fremtiden.
Den første tjenesten ble satt i produksjon på Kubernetes helt tilbake i 2015, faktisk på Kubernetes versjon 1.6. Sett i ettertid, og med den innsikten vi har nå etter å ha driftet Kubernetes og løsninger på Kubernetes i seks år, er det lett å tenke at ikke alle valgene vi tok innlednigsvis nødvendigvis var like gjennomtenkte. Men vi har lært ekstremt mye ved å være tidlig ut. Og Geodata liker å ligge i forkant teknologisk. En stor del av det vi gjør er å eksperimentere med teknologi, og se hva som fungerer og ikke fungerer.
Hvordan håndterer dere deploy til serverene? 🚗
Vi hoster kildekoden vår i Azure DevOps, og vi benytter stort sett Azure DevOps CI/CD piplenes til deploy. Egne byggagenter i Kubernetes skaleres etter behov og deployer til clusteret.
Vi har også skrevet en del egne Kubernetes-operatorer som bygger og tilgjengeliggjør tjenester automatisk, ved endringer i Kubernetes-manifester i git.

Hva bruker dere til å holde oversikt over drift? 📈
Vi ganske stolte over monitorering- og overvåkingsløsningen som i hovedsak er basert på Prometheus, Cortex, Loki, Grafana og AlertManger.
Prometheus skalerer ikke godt nok for vår bruk, så vi benytter kun Prometheus til scraping av metrics med remote write til Cortex for lagring og spørringer mot metrics. Vi benytter Cortex i microservice-konfigurasjon med S3 som backend for lagring av time series data.
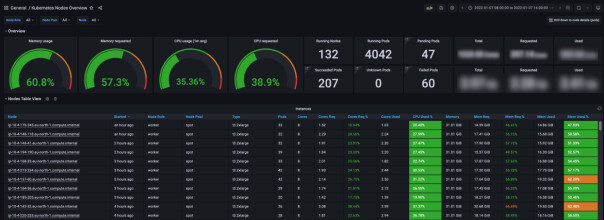
Metrics-systemet skalerer i alle ledd og håndterer normalt i overkant av 200.000 samples per sekund, og vi har omkring 4,3 millioner aktive time series. Alle metrics lagres i S3 og er tilgengelig i 9 måneder fra innsamling.
I tillegg har vi laget et overbygg på AlertManager som lar oss varsle hendelser via mail eller SMS til leveranseteam eller oss i DevOps-teamet. Denne løsningen består blant annet av AWS DynamoDB og AWS Lambda.

Hvordan håndterer dere caching? 💾
Hvert enkelt leveranseteam håndterer caching noe forskjellig.
Vi har instanser av memcached og redis kjørende i vårt cluster, som bistår med caching. For bakgrunnskartene lager vi cacher av disse hver uke med den mest oppdaterte informasjonen.
Cachen for bakgrunnskartene hostes så fra S3.
Hva bruker dere til domener og DNS? 📚
Domenene våre og DNS håndteres av Route53. Vi benytter oss av et prosjekt som heter external-dns i Kubernetes som ser på hvilke URL-er som ønskes i clusteret basert på ingress-objekter og alltid holder Route53 oppdatert.
Hvert enkelt leveranseteam står fritt til å opprette subdomener inne gitte rammer, en prosess som håndteres automatisk av external-dns. For sertifikater benytter vi CertManager med Let’s Encrypt.

Hva er det mest krevende når det kommer til drift hos dere? 😅
En god løsning for Cloud Native storage har lenge vært en utfordring.
I og med at plattformen per nå kjører på AWS, så er AWS Elastic Block Store (EBS) eller AWS Elastic File System (EFS) naturlig valg. Ingen av disse tjenestene fungerer optimalt i en Cloud Native kontekst på vår plattform på grunn av ulike begrensinger med tjenestene.
Vi har flere tusen POD-er på Kubernetes der mange trenger tilgang til lagring (PVC-er). Hurtig flytting av POD-er mellom tilgjengelighetssoner i AWS gir en del spesielle utfordringer. Vi har testet og hatt løsninger i produksjon på mange ulike lagringsalternativer, som Rancher Longhorn, NetApp ONTAP, Portworx, OpenEBS, Storage OS og Rook Ceph.
I dag benytter vi en kombinasjon av AWS EFS og Rook Ceph for Cloud Native lagring, men vi arbeider med å migrere lagring over til den nye AWS-tjenesten AWS FSx for NetApp ONTAP i kombinasjon med Trident CSI driver.
Hva bruker dere mest tid på i hverdagen, når det kommer til drift? ⏰
Vi bruker mye tid på å videreutvikle plattformen slik at konsulentene blir mest mulig selvdrevet.
I tillegg til dette svarer vi ofte på spørsmål om Kubernetes og plattformen vår internt.
Kontinuerlig oppdatering av alle komponentene plattformen består av tar også en del tid.

Hva er du mest fornøyd med å ha gjennomført i forbindelse med drift det siste året? 💪
Vi er veldig fornøyde med gjennomføringen av sikkerhets-patchingen av log4shell-sårbarheten. Det var en innsats som involverte store deler av organisasjonen vår.
I en hverdag med mye hjemmekontor, ble det en samlende øvelse hvor alle bidro for å tette sikkerhetshullet og kommunisere til de berørte på en forståelig og ærlig måte.
Teknisk sett har vi benyttet mye tid på å lage en helhetlig plattform med god dokumentasjon som gjør at prosjektteamene i Geodata kan operere etter et “self service” prinsipp. Vi har laget egne kontrollere og såkalte Custom Resource Definitions (CRDer) i Kubernetes for å forenkle en lang rekke arbeidsprosesser for konsulentene og utvikleren som benytter plattformen. Denne tilnærmingen var avgjørende for at Geodata klarte å håndtere en situasjon som log4j på en relativt smidig måte.
En annen teknisk løsning vi er ganske stolte av er hvordan vi holder styr på kostnadene for hvert enkelt miljø og løsning.
En annen teknisk løsning vi er ganske stolte av er hvordan vi holder styr på kostnadene for hvert enkelt miljø og løsning. I og med at vi drifter en felles multi-tenant Kubernetes-plattform for mange leveranseteam i Geodata, så er det viktig at hvert enkelt team får oversikt over hvor mye tjenestene og løsningen de publiserer på plattformen koster. Tradisjonelt er dette ganske enkelt på cloud-ressurser. Men i et delt Kubernetes-miljø med mange forskjellige nodegrupper, ressurstyper og skaleringsmekanismer er det langt fra trivielt å bergene en kostnad for minne, cpu, lagring, nettverk, lastsbalansering, cross zone kostnader og utgående trafikk mot internett.
Vi har laget egne kontrollere som baserer seg på Cortex for å beregne en løpende kostnad helt ned på container-nivå.

Hva har du lyst til å teste eller bytte ut fremover? 💸
Vi ser frem til å prøve "nested namespaces" i Kubernetes for å støtte bedre opp under vår organisasjonsstruktur hvor hvert leveranseteam kan få sitt namespace og lage separate prosjekter under dette.
AWS har etter hvert god støtte for maskiner som kjører på ARM. Disse er mer kostnadseffektive og yter bedre enn x86 til samme pris. Vi ønsker å eksperimentere med å flytte enkelte komponenter over til denne maskintypen som for eksempel ingresskontrollerene.
Foretrekk oss i Google Discover
Ved å legge oss til som foretrukket kilde i Google vil du blant annet få opp flere av sakene våre i Google Discover. Tusen takk for støtten!

































