
Sånn gjør Oslo Origo DevOps: – Ikke for pyser
Dropper Kubernetes til fordel for lettvekts container-styring.

Publisert
Etter noen år med mye Kubernetes går Origo gradvis over til mer “managed services” og lettvekts container-styring. Dette gir oss fleksibilitet og fart, men er ikke for pyser.
Origo er ikke mer enn fem år gammelt, men har allerede rukket å teste ut flere ulike modeller for infrastruktur.
Vi orienterte oss tidlig hovedsakelig mot Amazon Web Services (AWS). Det var dels fordi vi hadde få ressurser og mest kompetanse her, samtidig som løsningene der passet våre behov godt. Prinsippene og tankene bak ville nok vært tilsvarende om vi hadde gått i retning Google Cloud, Microsoft Azure eller andre leverandører.
Selvbygd standard grunnoppsett
Oslo kommune var, gjennom Utviklings- og kompetanseetaten, tidlig ute med moderne arkitektur og mikrotjenester i bakkant av fagsystemer og innbyggertjenester. Da Origo ble opprettet var det naturlig for oss å koble oss på eksisterende on-premise Kubernetes-infrastruktur. Selv om dette ble modernisert og flyttet opp i skyen, så vi behov for en løsning som var bedre tilpasset vår egen utviklingstakt og -fase. Med et renere fokus på utvikling av innbyggertjenester var det også ønskelig å selv ha hendene på rattet i større grad.
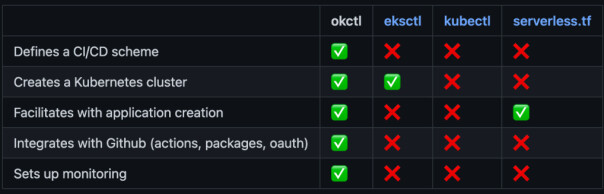
Et knippe driftige Origo-utviklere bygget okctl.io, et verktøy for å relativt enkelt kunne sette opp et standardisert produksjonsmiljø, gjennom konseptet rundt “Infrastructure as Code”, IAC. Fundamentet var fremdeles Kubernetes, gjennom Elastic Kubernetes Service (EKS) på AWS. “Team kjøremiljø” var dermed etablert som vårt kunnskapssenter for DevOps-kompetanse.

Utfordringer med selvbygd
Fordelene med Okctl var mange. Et standardisert oppsett ga utprøvde løsninger for utrulling, logging, sporbarhet, tilgang og sikkerhet. Skyggesiden, som begynte å dra ned utviklingsfarten vår, var at standardoppsettet ble litt begrensende for mange av teamene. AWS har bokstavelig talt hundrevis av ulike tjenester som kan være spennende for oss å både bruke og eksperimentere med.
Å bake inn flere og flere tjenester i denne standardpakka ble etter hvert krevende. Ulempene begynte å oppveie fordelene. Så hva tenker et autonomt team med DevOps-kompetanse da? “Kill your darlings.” Eller mer konkret: De skroter Okctl, bruker alt de har lært til å lage en enda bedre løsning, men i enda tettere samarbeid med brukerne.
Å bake inn flere og flere tjenester i denne standardpakka ble etter hvert krevende.
Origo er bygget opp rundt autonome team med stor forskjell i infrastruktur og kjørende tjenester. Kulturen med teamenes valgfrihet står sterkt. Samtidig prøver vi å ikke dra nisselua helt ned i øynene, og ser verdien av å ha enhetlige løsninger og driftsmiljøer der dette er hensiktsmessig.
Konseptet vi nå kaller “brolagt sti” begynte å ta form. Navnet er lånt fra Spotify sin lignende modell, og vi har hentet inspirasjon fra alt fra enabling teams (team kjøremiljø) i Team Topologies til (mangel på) samarbeid mellom funksjoner i The Phoenix Project. Brolagt sti adresserer forhåpentligvis mye av utfordringene vi opplevde med Okctl.
Brolagt sti vs selvbygd “black box”
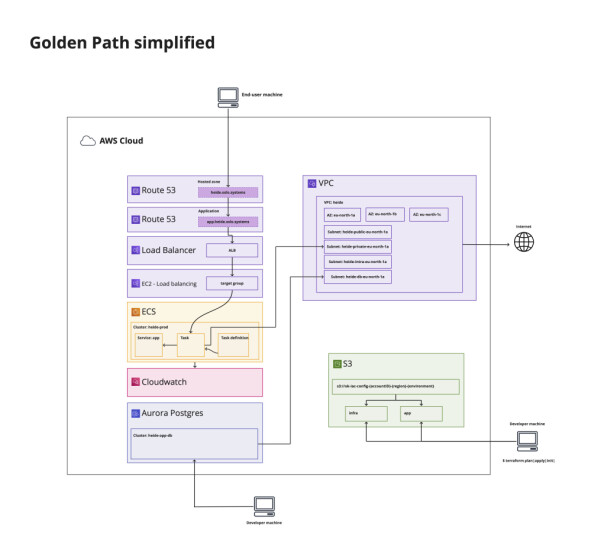
Gjennom brolagt sti bygger vi færre funksjoner inn i container-installasjoner vi selv må bruke mye tid på å vedlikeholde og oppgradere. I stedet fokuserer vi mer på å bygge kunnskap rundt hvordan man effektivt kan konfigurere og koble sammen alle typer AWS-tjenester (“Managed services”) de ulike teamene har behov for.
I praksis kan det bety at vi velger å konfigurere monitoreringsverktøyet Amazon Managed Prometheus i stedet for at vi selv setter opp en Docker-instans med Prometheus i et Kubernetes-cluster.
For oss fungerer Amazon sin mer lettvekts container-tjeneste, ECS, bedre enn Kubernetes.
Og det er kanskje greit å påpeke at vi ikke på noen måte vil ta livet av konseptet med containere – der det gir mening. Men for oss fungerer Amazon sin mer lettvekts container-tjeneste, ECS, bedre enn Kubernetes. Sistnevnte føltes litt for ofte som å skyte spurv med kanon for våre behov.
– Hah, da er dere i lomma på skyleverandøren, tenker du kanskje. Det har du nok rett i. Men det ekteskapet er i grunn inngått allerede. Selv om vi kan kjøre akkurat hva vi vil i Kubernetes-clusterne, så brukte vi allerede massevis av funksjonene til AWS for å sy det hele sammen.
Ved å ligge enda litt tettere i skje med AWS utnytter vi i stedet mer av ekspertisen, skaleringsmulighetene og innovasjonskraften til skyleverandøren. Om vi en vakker dag må, eller ønsker å, bytte skyleverandør, så har vi vurdert at jobben ikke blir sååå mye større at det oppveier fordelene vi har hatt verdi av underveis.
Et par ekstra bonuspunkter denne teknologivridningen har gitt oss:
- Et mer transparent oppsett gjør det lettere å gjøre risiko- og sårbarhetsanalyser
- Det er lettere for teamene å bidra med nye «steiner til stien» …
- ... og det er enklere å gå utenom stien ved behov

Teknologi-prinsipper
Vi innfører altså et nytt og friere oppsett, i en verden som allerede er ganske autonom. Da ser vi en viss risiko for at vinninga går opp i kaos og spinning, om vi ikke har tenkt noen tanker rundt prinsipper og ansvarsfordeling. Disse tankene, og spesielt arbeids- og ansvarsfordelingen, jobber vi kontinuerlig med, og justerer mens vi går.
Det ble tidlig tatt et valg i Origo om at team som standard skal ha sin egen AWS-konto, bortsett fra i noen få tilfeller hvor det er spesielt hensiktsmessig å dele konto.
Dette valget er begrunnet i at det:
- understøtter autonomien til teamene i Origo
- gir god separering og god skalerbarhet
- begrenser omfang ved sikkerhetshendelser
- tydeliggjør ansvaret som ligger hos hvert produktteam
Med forskjellige AWS-kontoer som utgangspunkt, er det lagt opp til separat infrastruktur for hvert enkelt team. Men man ønsker like fullt en uniform infrastruktur på tvers av teamene. Dette er viktig for å:
- opprette sikre og gode oppsett, som følger beste praksis
- legge til rette for kunnskapsdeling og brukerstøtte på tvers av team
- legge til rette for flyt av utviklere på tvers av team
- legge til rette for at team kjøremiljø kan bli spesialister på infrastruktur og plattform

Team kjøremiljø skal hjelpe produktteamene med å gjøre det enklere å håndtere sin egen AWS-konto. Dette gjør de ved å utvikle og tilgjengeliggjøre felles verktøy og felles maler for “brolagt sti”.
Det innebærer at team får ferdig konfigurasjon for sine vanlige tekniske oppsett som kjøring av applikasjoner, hosting av nettsider, loggaggregering, samling av metrikker, osv. Bruk av managed løsninger forenkler også driften, da AWS håndterer oppgraderinger, restarter, osv.
Risikoer
Denne måten å håndtere sine kjøremiljøer på kommer naturlig nok ikke helt uten en viss risiko. Vi får betydelig økt fart og frihet, men er ekstra oppmerksomme på slitasjesignaler:
Driftsansvar kan være utenfor komfortsonen
Det hviler et stort ansvar på produktteamene, da de har ansvar for egen infrastruktur i tillegg til applikasjonsdrift. Dette krever bred kompetanse hos utviklere, og det er forskjell på hvor god DevOps-kompetanse som finnes på hvert team. Dette oppsettet øker den kognitive lasten hos hver utvikler, men det er viktig å huske at vi har kompetanse utenfor et team som kan hjelpe ved behov.
Origo jobber også aktivt med opplæring og felles kompetansetiltak for å hjelpe med denne utfordringen.
Rigid ansvarsfordeling krever hjelpekultur
Med driftsansvar hos hvert enkelt produktteam trenger vi en god kultur for å hjelpe hverandre. Det gjelder både når man setter opp infrastruktur og ved utfordringer i driften. Det er viktig med godt samarbeid på tvers av produktteam, hvor vi spiller hverandre gode og er åpne for å bistå ved behov. Team kjøremiljø vil også kunne hjelpe som en spesialist på mye av infrastrukturen som brukes.
Fortsatt uklarheter om ansvarsfordeling
Denne beskrevne ansvarsfordelingen er ikke komplett eller endelig. Det kan fortsatt oppstå uklarheter og grensetilfeller i fordelingen. Disse må håndteres fortløpende.
Fare for uhensiktsmessig høy tidsbruk
Teamene jobber til daglig mest med egne applikasjoner og produkter. Med mye ansvar for egen infrastruktur hos hvert produktteam kan det føre til stor belastning både kognitivt og i arbeidsmengde. Vil tiden brukt på infrastruktur- og driftsoppgaver i Origo som helhet kunne bli uhensiktsmessig høy?
Det er viktig at produktteam har nok infrastrukturkompetanse og at team kjøremiljø er stort nok til at de får bistått produktteam tilstrekkelig. I tillegg må løpende teknologivalg søke å avlaste teamene.

Gevinster og effekter
Det er for tidlig å si hvilke langsiktige effekter vi får av denne omleggingen. Etter en intens omleggingsperiode på en måneds tid for hvert team, tikker det nå greit. Litt forenklet kan vi anslå at mengden ukentlig arbeid med infrastruktur er omtrent som før. Men det er en del vesentlige forskjeller:
- Det er mer motiverende å lære seg infrastrukturverktøy som er industristandard. (Terraform støtter eksempelvis alle de store skyplattformene, mens CloudFormation var AWS-spesifikt.)
- Nyansatte med f.eks Terraform-kompetanse fra andre plattformer kan bidra umiddelbart
- Det er et mye større community av kunnskap å hente hjelp fra
- Teamene har mer frihet i valg av komponenter de trenger til akkurat sine produkter
- Oppsettet er ikke lenger en “black box”, men teamene vet selv hvordan alt henger sammen. Det gjør feilsøking betydelig enklere.
- Fremdeles har teamene svært mange godt utprøvde standardkomponenter å bruke
Det har ikke vært en avgjørende driver for omleggingen, men vi sparer også en del penger på å ha oppsett som er bedre skalert for det enkelte team.
Visjonen er å gjøre det enkelt for en koder som til daglig ikke holder på med infrastruktur å finne veien selv når det er problemer eller behov. Og så er team kjøremiljø der som støttehjul, sparringspartnere og evangelister.
Kanskje går vi mot strømmen med å vinke farvel til Kubernetes. Overgangen koster litt, både i tid og grubling.
I noen team er hele teamet bevisst investert i infrastrukturforståelsen, mens det hos andre er 1–2 champions som tar det meste. Dette harmonerer godt med autonomien Origo generelt prøver å praktisere for alle utviklerteamene.
Kanskje går vi mot strømmen med å vinke farvel til Kubernetes. Overgangen koster litt, både i tid og grubling. Men så langt ser dette ut til å kunne gi raske resultater i både utviklertrivsel og evne til å levere bedre innbyggertjenester raskere.
💡 Vil du lese mer om anvarsfordelingen, finner du dette i det opprinnelige innlegget på labs.oslo.kommune.no.

Foretrekk oss i Google Discover
Ved å legge oss til som foretrukket kilde i Google vil du blant annet få opp flere av sakene våre i Google Discover. Tusen takk for støtten!































