Hva er viktigst for norske utvikleres lønn? Tommy har regna
– Arkitekter høy lønn, men de har også lang erfaring. Så hvor mye av lønna bør tilskrives fagfeltet? skriver Tommy Odland, mannen bak modellen bak kode24s lønnskalkulator.

Publisert
Kode24 har publisert data fra sin spørreundersøkelse om lønn. Her kommer en analyse av tallene. Resultatet er ganske likt som i min analyse av 2023-tallene.
Det er ti variabler i datasettet.
Variablene er ikke bare korrelerte med lønna, de er også korrelerte med hverandre. Eksempelvis har arkitekter høy lønn, men de har også lang erfaring. Så hvor mye av lønna bør tilskrives fagfeltet heller enn erfaringen?
For å svare på dette skal vi dekomponere variablene ved hjelp av en Generalisert Additiv Modell (GAM).
💡 Vil du teste ut Tommy Odlands modell i praksis? Sjekk ut kode24s nye lønnskalkulator på kodejobb.no!
Mange feilkilder
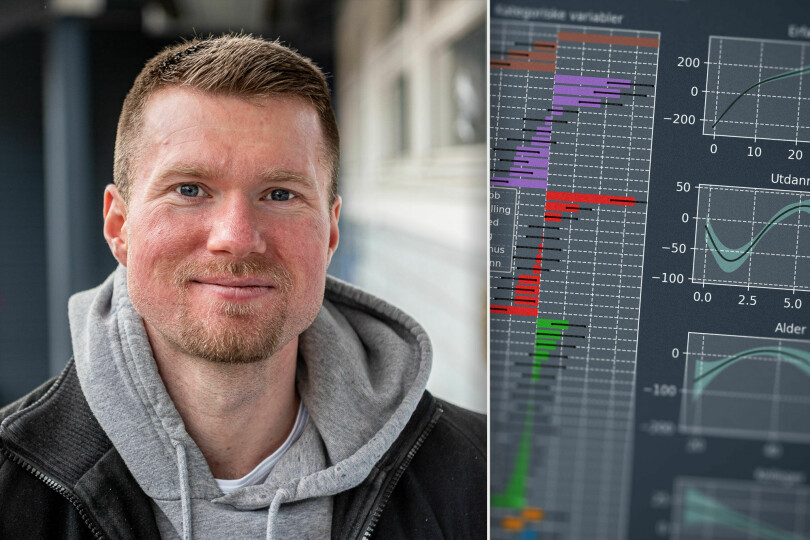
Vi begynner med konklusjonen av analysen, som er oppsummert i figuren nedenfor:
Seks variabler er kategoriske og fire er numeriske. Effekten av hver variabel er vist som en differanse fra modellens konstantledd, som er en lønn på 970 tusen kroner (TNOK). Usikkerheten i effektene er også vist i figuren.
Antall personer i hver kategori er vist i parentes. Frilans har en koeffisient på 250 TNOK, men ble kuttet i figuren for å vise helheten bedre.
Vi skal være forsiktige med å tolke et slikt datasett og tilhørende analyser med stor sikkerhet. Det er mange feilkilder: Dataene er selvrapporterte, kode24-lesere er ikke nødvendigvis representative for IT-folk generelt, den statistiske modellen gjør visse antagelser og det er usikkerhet i effektene som modellen plukker opp.
La oss ta noen skritt tilbake og jobbe oss frem til resultatet ovenfor steg for steg, samtidig som vi gjør syv observasjoner.

#1: Medianlønna er 850 TNOK
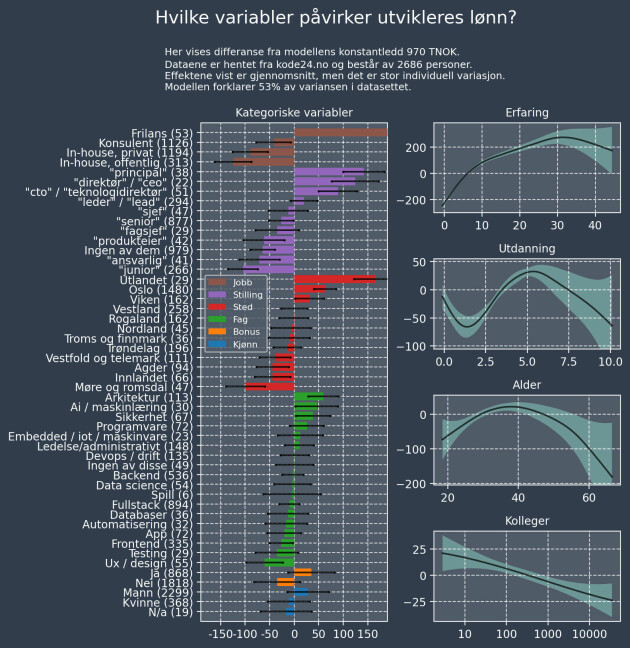
Vi begynner med å plotte fordelingen av lønna. Tvilsomme datapunkter som sannsynligvis var feilrapporterte har blitt fjernet.
Figuren nedenfor viser at medianlønna er 850 TNOK og at halvparten har lønn mellom 700 og 1010 TNOK.
På bunnen av figuren er 200 tilfeldige personer vist.
#2: En additiv struktur forklarer datasettet godt
Vi skal nå bruke et utvalg fra datasettet til å forklare hvordan den additive modellen fungerer.
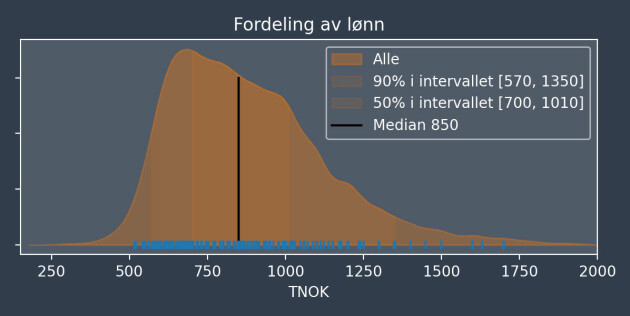
Figuren til venstre nedenfor viser utviklere fordelt i 15 grupper basert på fag og sted. Innad i hver gruppe er medianlønna vist. Totalt sett er medianlønna 850 TNOK.
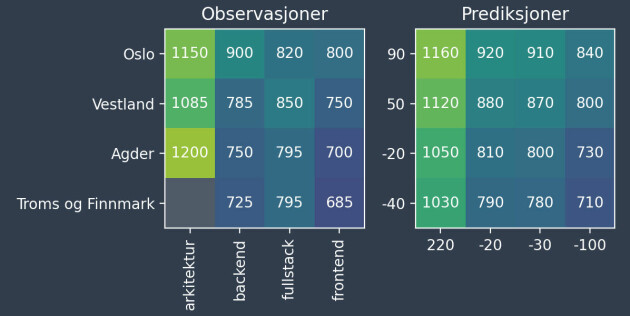
Arkitekter i Oslo har en medianlønn på 1150 TNOK. Både stedet (Oslo) og faget (arkitekt) tilsier at gruppen skal tjene godt. Hvor mye av den høye lønna bør da tilskrives hver variabel?
For å svare på dette bruker vi en additiv modell. Vi assosierer en numerisk koeffisient med hvert sted og fagfelt, som deretter legges på medianen 850 TNOK for å estimere lønna. Stedet Oslo får koeffisienten 90 TNOK og fagfeltet arkitektur får koeffisienten 220 TNOK. Modellen estimerer derfor at arkitekter i Oslo tjener 850 + 90 + 220 = 1160 TNOK.
Arkitekter i Oslo tjener i størst grad godt fordi de er arkitekter, ikke fordi de bor i Oslo. Modellen lar oss estimere hva en typisk arkitekt i Troms og Finnmark ville tjent, selv om ingen slike personer finnes i datasettet. Den additive modellstrukturen er enkel, forståelig og beskriver datasettet godt.

#3: Vi bør være forsiktige med årsakssammenhenger
Ovenfor sa vi at lønna "skyldes" en variabel og at noen tjente godt "fordi" de er arkitekter. Denne språkbruken er i kontekst av en dekomposisjon av variabler i et datasett, og er ikke ment som en kausal tolkning av virkeligheten.
Vi vet at korrelasjon ikke er det samme som kausalitet, men betyr det at vi ikke kan si noe om årsakssammenhenger? Statistikere har lenge drøftet nyansene i dette spørsmålet, og det finnes ingen enkel fasit.
Virkeligheten er kompleks og effektene som en modell finner kan skyldes både korrelasjon og kausalitet. Det er ikke nødvendigvis galt å spekulere i årsakssammenhenger, men husk at en statistisk modell alene ikke sier noe om årsak – bruk sunn fornuft og vær forsiktig med bastante konklusjoner.

#4: Variabler er korrelerte
La oss undersøke hvordan en additiv modell kan dekomponere en numerisk variabel (erfaring) og en kategorisk variabel (stilling). Her er et eksempel der variablene er sterkt korrelerte:
- En typisk person med "junior" i stillingstittelen har ett års erfaring og tjener 630 TNOK.
- En typisk person med "senior" i stillingstittelen har åtte års erfaring og tjener 945 TNOK.
I hvor stor grad skyldes lønnsforskjellen stillingstittelen kontra erfaringen? Modellen antar en numerisk koeffisient per stillingstittel og en glatt funksjon for erfaring.
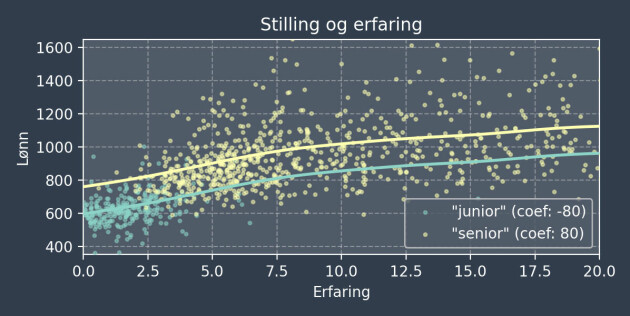
Modellantagelsen er at lønnsøkningen som funksjon av erfaring er den samme, og at stillingstittelen gir et påslag i form av en koeffisient.
Gitt lik erfaring anslår modellen at en typisk senior tjener 80 - (-80) = 160 TNOK mer enn en junior. Om vi ikke korrigerer for erfaring er differansen mellom en senior og en junior lik 945 - 630 = 315 TNOK.
Tidligere så vi hvordan modellen dekomponerte to kategoriske variabler (sted og fag). Her ser vi hvordan modellen dekomponerer en kategorisk variabel (stilling) fra en numerisk variabel (erfaring). Den endelige modellen dekomponerer alle de ti variablene samtidig.
#5: Estimater er usikre
Modellen estimerer effekten av alle variablene samtidig. Usikkerheten i estimatene påvirkes av spredningen i lønna, antall svar i spørreundersøkelsen og hvor mange koeffisienter som estimeres samtidig.
Figuren nedenfor viser usikkerheten i de glatte funksjonene som estimerer effekten av numeriske variabler på lønna.
Når erfaringen øker blir usikkerheten større, fordi det er få personer med lang erfaring i datasettet. Denne typen usikkerhet forekommer i alle estimater, også i effekten av kategoriske variabler som sted og fagfelt.
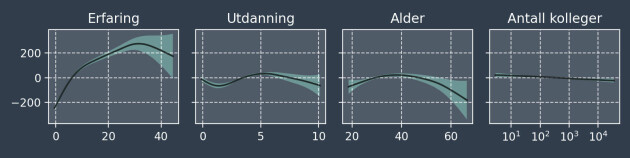
At det er lite usikkerhet forbundet med effekten av erfaring de første ti årene betyr at vi er sikre på den generelle trenden. Det betyr ikke nødvendigvis at vi med sikkerhet kan predikere lønna til et enkeltindivid.
#6: Noen få variabler gir gode prediksjoner
La oss bruke en modell til å predikere lønna til enkeltindivider. Vi bruker Mean Absolute Error (MAE) som mål på prediksjonsfeil og undersøker tre ulike modeller:
- En enkel modell som bare har et konstantledd og alltid gjetter medianen
- Vår forklarbare additive modell (GAM), med ulike antall variabler
- En Gradient Boosting (GB) maskinlæringsmodell
En modell som bare bruker et konstantledd (medianen) har en typisk feil på 213.7 TNOK.
Om vi får bruke én variabel i en GAM bør vi velge erfaring, som reduserer feilen til 148.2 TNOK. Får vi legge til enda en variabel bør vi velge jobb, som tar feilen ned til 140.5 TNOK. Slik fortsetter vi til alle variablene er med og feilen er 129.1 TNOK. Å ta med kjønn forverrer modellen litt ettersom den overtilpasser og generaliserer dårligere.
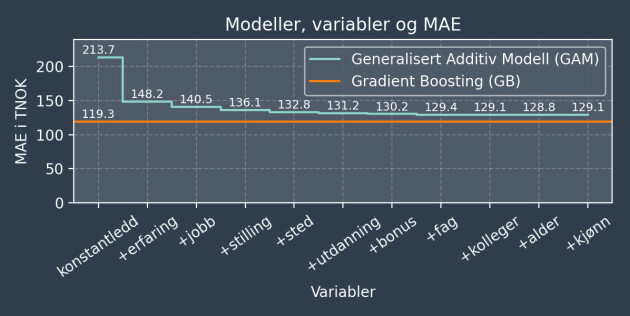
GB har en typisk feil på 119.3 TNOK, som er litt bedre enn GAM, ettersom GB ikke er begrenset til en additiv struktur. Formålet med analysen bør diktere modellvalget, og her er hovedformålet innsikt og forståelse. Vi bruker derfor GAM heller enn GB, selv om det også er mulig å trekke mye innsikt ut av black-box modeller som GB.
Noen få variabler er alt vi trenger for å predikere rimelig godt. Modellene halverer prediksjonsfeilen sammenlignet med å bruke medianen. Den resterende halvparten av lønnsforskjellene ikke er forklart av variablene i datasettet.
#7: Erfaring er viktigst
Det finnes mange mål på hvor viktige variabler er i en modell. En metode er å stille følgende spørsmål: Gitt at vi kan bygge en modell med kun én variabel, hvilken bør vi velge?
Dette gjorde vi i forrige seksjon, og svaret var erfaring.
En annen metode er permutation importance. Litt forenklet er idéen å først trene en modell på alle variablene. Deretter bruker vi den til å predikere, men vi lar folk lyve om én variabel. Hvor mye prediksjonskraft taper vi dersom folk er uærlige?
Resultatene er vist i figuren nedenfor. Om du lyver om erfaring vil det gå kraftig ut over modellens evne til å predikere lønna di. Om du lyver om de andre variablene har derimot mindre å si, og disse variablene kan derfor anses som mindre viktige.
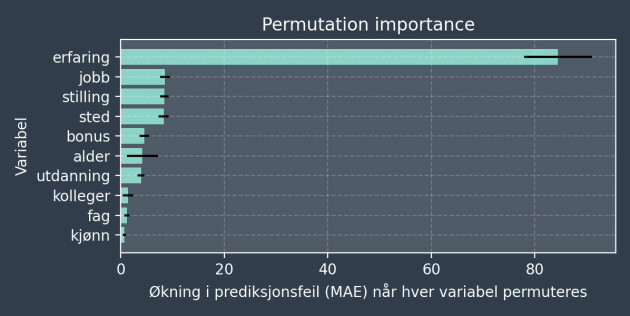
Det enkleste argumentet for at erfaring er viktig er å se på figuren som oppsummerer modellen. Forskjellen mellom kort og lang erfaring er omtrent en halv million kroner i årslønn, som er langt mer enn effekten av noen annen variabel.

Oppsummering og referanser
Datasett som dette bør tolkes forsiktig, men vi kan likevel lære mye av å analysere dataene.
Nåtidens fokus på maskinlæring og AI kan gi inntrykk av at formålet med alle modeller er prediksjon. Her var derimot hovedfokus innsikt, og vi forklarte halvparten av lønnsforskjellene ved hjelp av ti variabler. Jeg brukte min egen Python-pakke generalized-additive-models til analysen.
Jeg håper du fikk forståelse for hvilke faktorer som er med på å påvirke lønn, samtidig som du forhåpentligvis lærte litt om statistisk modellering. Denne gangen var problemstillingen lønn, men metodene og modellene er generelle.
I dag har vi mer data, kraftigere maskiner og flere mennesker som analyserer data enn noen gang – statistikk er derfor viktigere enn noensinne.

Om man vil lese populærvitenskapelige introduksjoner til statistikk kan jeg anbefale:
- Flaws and Fallacies in Statistical Thinking, av Campbell
- The Book of Why, av Pearl
- The Lady Tasting Tea, av Salsburg
Ønsker man faglitteratur for modelling ville jeg startet med:
- Regression and Other Stories, av Gelman
- Statistical Rethinking, av McElreath
💡 Vil du teste ut Tommy Odlands modell i praksis? Sjekk ut kode24s nye lønnskalkulator på kodejobb.no!

Foretrekk oss i Google Discover
Ved å legge oss til som foretrukket kilde i Google vil du blant annet få opp flere av sakene våre i Google Discover. Tusen takk for støtten!


































