Selvstendige utviklere tjener mest: «Overraskende stor forskjell»
- Om man er selvstendig eller ikke, har mer å si enn hvor man bor og hva man jobber med, skriver Tommy Odland i sin analyse.

Publisert
kode24 har publisert data fra spørreundersøkelsen om lønn for 2023. Datasettet ligger også på Kaggle.
Nedenfor er resultatet av min analyse oppsummert i én figur. Les videre for flere kommentarer om datasettet og modelleringen.
Tallene og analysen må tolkes forsiktig. Lønnstallene er selvrapporterte og kode24-lesere er sannsynligvis ikke representative for utviklere generelt.
Her er mine observasjoner:
#1: Det er stor variasjon i lønn generelt
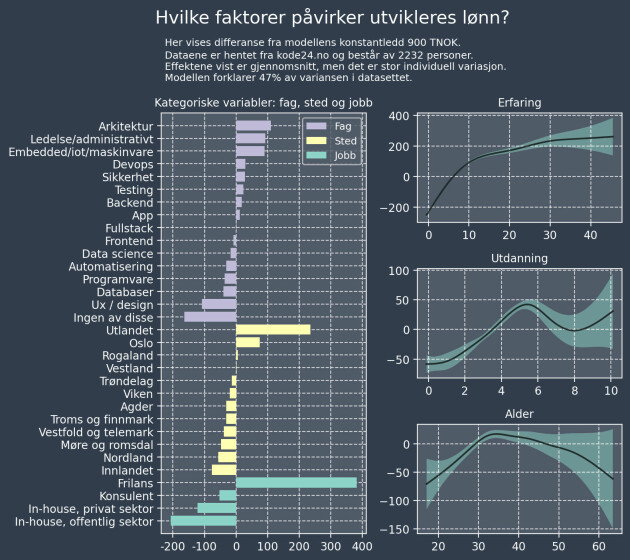
- Median-lønna er 790.000 kroner
- Halvparten av utviklerne ligger i intervallet [650,960]
- 90% av utviklerne ligger i intervallet [500,1330]
Om vi plotter persentiler i lønn opp mot mot erfaring, ser det omtrent slik ut:
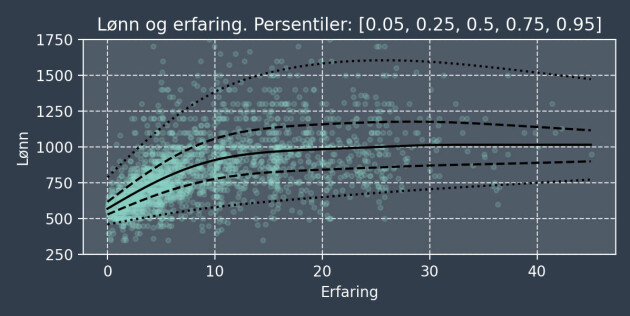
Om vi plotter alle numeriske variabler, ser vi hvor svake sammenhengene er. I figuren nedenfor er det lagt på litt støy, og vi har tatt logaritmen av lønna:
Selv en kompleks maskinlæringsmodell forklarer bare halvparten av variansen i datasettet.
Om du ikke har noen informasjon om en person, og prøver å gjette lønna til personen, vil du gjette medianen 790.000 kroner om du prøver å minimere Mean Absolute Error (MAE). Denne strategien gir deg en 10-fold out-of-sample MAE på 200.000. Du vil gjette feil ofte, og du vil typisk gjette to hundre tusen kroner feil.
Om du derimot har informasjon om utdannelse, alder, erfaring, og alt det andre, så gjør du det fremdeles ikke så mye bedre. En gradient boosting modell gir en MAE på 135.000, så selv med en kompleks maskinlæringsmodell og masse informasjon har du bare redusert MAE med en tredjedel sammenlignet med å gjette medianen.
Det er mange grunner til at folk har ulik lønn, og de fleste grunnene er ikke i dette datasettet.

Hvor stor andel av forskjellen skyldes fagfelt, og hvor mye skyldes erfaring?
#2: Vi bør bruke en modell for å forstå hvem som har høy lønn
Det er mulig å analysere disse dataene uten å bruke en modell, men det er bedre å bruke en modell.
I analysen ovenfor skriver journalisten at “som vanlig her i samfunnet, er det altså lederne som tar den største biten av kaka.” Han refererer til at ledere i snitt tjener 1.150.000 kroner, mens f.eks. frontendere tjener 775.000 kroner.
Deretter skriver han at “i undersøkelsen vår er det også ledere og arkitekter som har lengst erfaring.” Dette er en viktig observasjon som forklarer mesteparten av lønnsforskjellen—ledere har i snitt 14 års erfaring, mens frontendere i snitt har 6 års erfaring.
Et naturlig neste spørsmål å stille er: Hvor stor andel av forskjellen skyldes fagfelt, og hvor mye skyldes erfaring?
Det er akkurat dette modellen svarer på! Modellen korrigerer for erfaring og alle andre variabler, og viser oss at effekten av å være leder er omtrent 100.000, ikke 1.150.000 − 775.000 = 375.000.
En god modell støtter en analyse ved å plassere effekter der de hører hjemme. Det lar oss forstå sammenhenger selv når variabler er korrelerte, slik som eksempelvis fagfelt og erfaring er. Ulempen er at modeller har sine egne innbakte antagelser, så man må modellere riktig og bruke sunn fornuft.

#3: Vi bruker en forklarbar modell: GAM
I denne analysen bruker vi en Generalisert Additiv Modell (GAM) for å modellere ikke-linearitet i kontinuerlige variabler. En GAM er en sum av effekter. Vi summerer effekten av erfaring, effekten av utdanning, etc—men hver av disse effektene kan være ikke-lineære (se første figur). Selv om dette er en strukturelt enkel modell, bruker vi den fordi vi er ute etter forståelse og forklarbarhet, ikke ren prediksjonskraft.
Når det er sagt, mister vi ikke mye prediksjonskraft heller. Her er 10-fold out-of-sample R^2 og RMSE i tusen kroner, for noen ulike modeller.
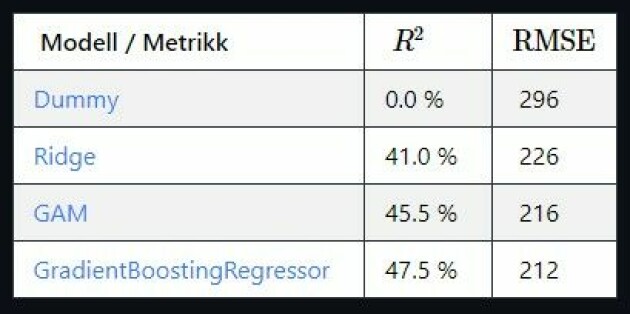
GAM er bare to prosentpoeng bak en kompleks, black-box GradientBoostingRegressor i forklart varians—en liten pris å betale for en enkel og forståelig modell!
#4: Erfaring betyr mye
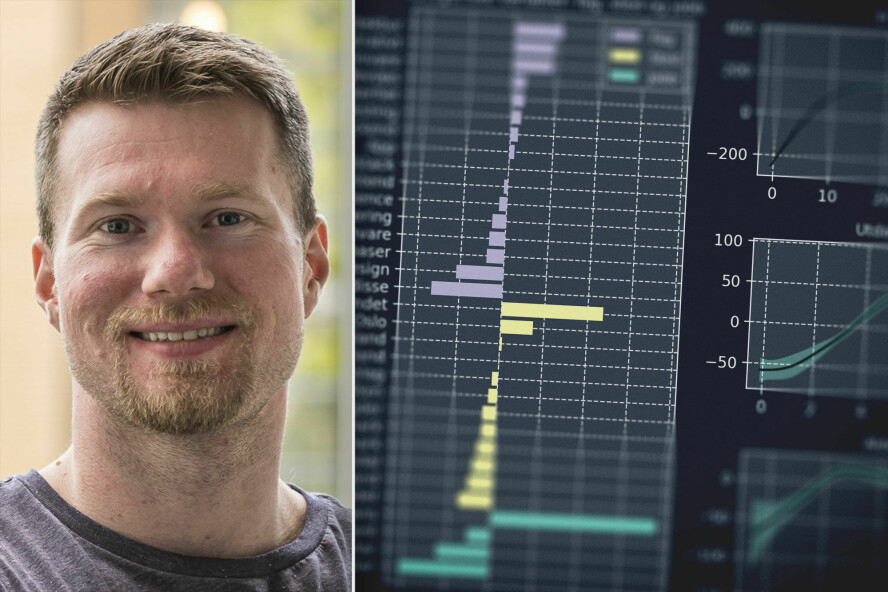
Her er effekten av de tre kontinuerlige variablene: erfaring, utdanning og alder. Effektene er additive, og tallene på y-aksen legges til modellens konstantledd, som er 900.000 kroner.
Når vi bruker samme y-akse ser vi hvor avgjørende arbeidserfaring er på lønna:
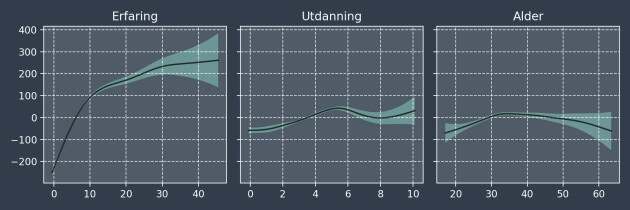
- Erfaring betyr mye, og fører til lineær lønnsøkning de første 10 årene, før effekten flater ut
- Utdanning gir en positiv effekt de første 5 årene (mastergradsnivå), før det flater ut
- Den beste alderen er midten av 30-årene
Når det gjelder alder, må man tolke modellen svært forsiktig. Husk at figuren ovenfor viser effekten av alder, gitt erfaring og utdanning. Har man x år med erfaring, ser det ut som at man får mest lønn når man er omtrent 30 år. Alder og erfaring er selvsagt sterkt korrelert, og man kan ikke ha erfaring uten alder.

#5: Selvstendig næringsdrivende tjener mest
Det er kanskje ikke overraskende at de selvstendige tjener mest. Likevel er det overraskende at forskjellen er så markant.
Om man er selvstendig eller ikke, har mer å si enn hvor man bor og hva man jobber med:
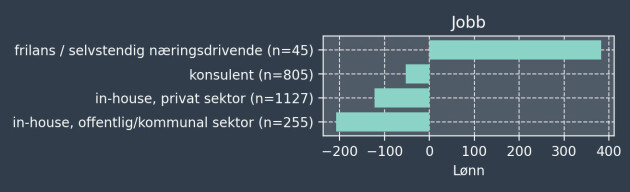
Vi visualiserer ikke usikkerheten i koeffisientene, men lønnen til selvstendig næringsdrivende er naturligvis forbundet med noe høyere usikkerhet ettersom det bare er n=45 personer i denne gruppen.

#6: Vi må være forsiktige med årsakssammenhenger
Ovenfor så vi at det er en sammenheng mellom det å være selvstendig konsulent og å tjene godt. Selv om det til en viss grad er rimelig å anta at å være selvstendig fører til høy lønn, må vi passe oss for skråsikre kausale tolkninger.
De selvstendige tjener mer i snitt. Men det betyr ikke at en vilkårlig konsulent som bestemmer seg for å bli selvstendig, vil ende opp med å tjene mer, fordi:
- Det er stor variasjon innad i gruppene
- Ikke alle kombinasjoner er relevante, f.eks. å være selvstendig uten erfaring eller utdanning
- Det er tenkelig at en annen underliggende variabel utøver kausal effekt på både lønn og om man er selvstendig, f.eks. hvor risikovillig eller dyktig eller ambisiøs man er
- Mange av de som prøver seg som selvstendige, men ikke lykkes i å øke lønna, går kanskje tilbake til faste stillinger
Når alt det er sagt, er det heller ikke urimelig å anta at en del konsulenter hadde tjent mer om de ble selvstendige.
...heller ikke urimelig å anta at en del konsulenter hadde tjent mer om de ble selvstendige.
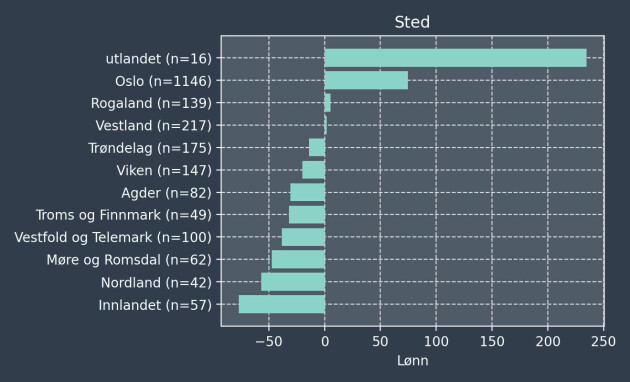
#7: Bosatte i Oslo og utlandet har høyest lønn
Effekten av geografisk lokasjon er vist i figuren nedenfor. De som jobber i utlandet har høyest lønn, men igjen må vi være forsiktig med usikkerheten når det kun er n=16 personer i denne gruppen. At IT-folk i Oslo tjener mest i Norge er det derimot liten tvil om.
Effekten av å jobbe i Oslo kontra Innlandet ser ut til å være omtrent 150.000 — en respektabel sum, men forskjellen dekker neppe differansen i boligkostnader:

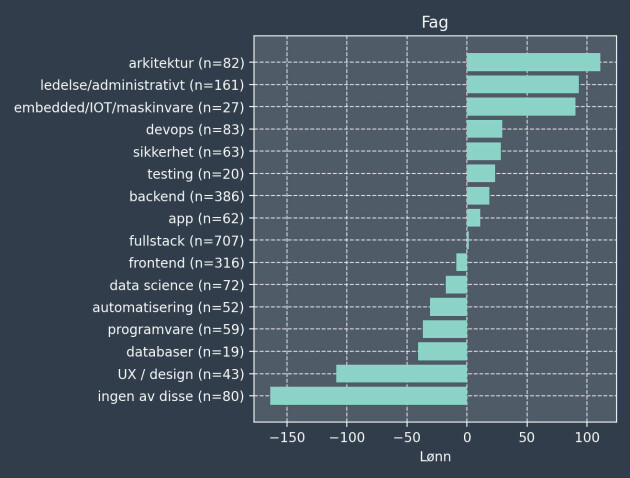
#8: Arkitekter tjener mest, designere tjener minst
Her er oversikten over hvilke arbeidsoppgaver som er assosiert med høyest og lavest lønn:

Referanser og kommentarer:
- Her er formålet med modellen forståelse, ikke prediksjon. Dette er mer statistikk enn maskinlæring. Lineære modeller eller generaliseringer som GLMs og GAMs er i min erfaring gode valg.
- I denne notebooken får Ole-Magnus en MAE på 140.000 med en lineær regresjon, og 132.000 med en boosting-modell. Lineær regresjon konkurrerer godt mot boosting, og dette er typisk for problemstillinger som denne.
- I denne notebooken bruker Tomas Shapley-verdier til å forklare en xgboost-modell. Jeg foretrekker å bruke en transparent modell som en GAM, heller enn å legge Shapley-verdier på en black-box modell.
- Jeg brukte min egen Python-pakke generalized-additive-models til modellering.

Foretrekk oss i Google Discover
Ved å legge oss til som foretrukket kilde i Google vil du blant annet få opp flere av sakene våre i Google Discover. Tusen takk for støtten!


































