
Amazon Aurora DSQL: «Gjør mye riktig, men mye mangler»
AWS-nyhet lover distribuert SQL-database med digre skaleringsmuligheter, men bør du hive deg på? Vemund M. Santi og Jens Mæland dykker ned.


Publisert
Under fjorårets re:Invent lanserte AWS sin nyeste tjeneste Amazon Aurora DSQL, en distribuert SQL-database med tilnærmet uendelige skaleringsmuligheter, minimum garantert oppetid på 99.99% og en elastisk skaleringsmodell som gjør den fullstendig serverless.
Rett etter re:Invent var den kun tilgjengelig i preview i enkelte regioner, men i slutten av mai ble den gjort generally available i regioner over hele verden.
DSQL utfordrer hva som tidligere har vært mulig med distribuerte, relasjonelle databaser, på samme måte som Googles Spanner tøyer strikken for hva som er mulig å få til av ACID-garantier i et distribuert system.
Så, hvordan klarer man å bygge en database på tvers av geografiske regioner som fortsatt kan garantere konsistent lagring ved parallell lesing og skriving?
I denne artikkelen skal vi gjøre et dypdykk i hvordan DSQL er satt sammen, og titter på nyvinningene som gjør Amazon Aurora DSQL til en sterk database-konkurrent i et klima med stadig høyere krav til tilgjengelighet og oppetid.
Hva er greia?
Aurora DSQL er optimalisert for transaksjonelle arbeidsbelastninger (OLTP), det vil si hyppige oppdatering og lesing av noen få rader av gangen i kontrast til analytisk arbeid (OLAP), hvor fokuset er på å lese store mengder data av gangen. Transaksjonelle arbeidsbelastninger er typisk hva en bruker innen bransjer som bank og finans, e-handel, detaljhandel og andre tjenester hvor brukere selv interagerer og oppdaterer sine egne data.
Tidligere har vi sett at slike distribuerte og uendelig skalerbare databaser har fokusert på OLAP, hvor målet er aggregering av data og statistikk og hver enkelt rad spiller en mindre viktig rolle i den store sammenhengen. I teorien er det mye lettere å skalere en slik database ettersom en kan ta seg enkelte friheter når det gjelder datakonsistens og nedprioritere ytelse på små oppdateringer. Et godt eksempel på dette er Amazon Redshift, datavarehus-løsningen til AWS.

Dermed er det ekstra spennende når en har klart å gjøre det samme med OLTP:
- DSQL tilbyr relasjonell funksjonalitet som transaksjoner og joins, i tillegg til sterkt konsistent datatilstand og snapshot-isolasjon.
- Grensesnittet det hele er tilbudt gjennom er den gode og velkjente SQL-standarden, så en kan enkelt benytte eksisterende kunnskap og migrere uten å måtte lære seg et helt nytt språk eller API.
- Videre er grensesnittet PostgreSQL-kompatibelt, som tilbyr en hel haug av ekstra funksjonalitet og gjør det en del enklere å skrive spørringer som ellers ville vært unødvendig komplisert om en kun skulle holde seg til helt nøyaktig SQL.
Nå sitter du kanskje og tenker “Men alt dette finnes jo allerede i en helt standard PostgreSQL-database?”. Det er helt riktig. Der Aurora DSQL virkelig begynner å skinne er når du tar all denne funksjonaliteten og klarer å sette det i en kontekst av en distribuert modell, hvor ikke kun lesing fra databasen kan avlastes til andre instanser, men selve skrivingen også foregår andre steder enn “hovedinstansen” i databaseclusteret.
Det som gjør DSQL spesiell er muligheten til å både lese og skrive fra alle instanser i det distribuerte systemet.
Distribuert database
I tradisjonelle database-arkitekturer har vi ofte løsninger hvor en kan distribuere leseoperasjoner til flere instanser for å øke ytelsen, mens all skriving fortsatt må gå gjennom en enkelt primærnode.
Dette fungerer godt for mange bruksområder, men skaper naturlige flaskehalser når skrivevolum øker eller når geografisk distribusjon er påkrevd.
- Det som gjør DSQL spesiell er muligheten til å både lese og skrive fra alle instanser i det distribuerte systemet.
- Dette betyr at applikasjoner kan utføre INSERT-, UPDATE- og DELETE-operasjoner mot hvilken som helst tilgjengelig database-instans, uavhengig av hvor den befinner seg geografisk.
- Samtidig garanterer systemet at alle instanser til enhver tid har et konsistent syn på dataene - et problem som tradisjonelt har vært svært komplekst å løse uten å ofre enten ytelse eller tilgjengelighet.
Så, hvordan fungerer det? Det er flere byggeklosser som må til for å kunne oppnå ACID garantier i et distribuert system. Vi ser nærmere på noen av genialitetene som får det hele til å henge sammen.
#1: Aktiv-passiv vs aktiv-aktiv
En Aktiv-passiv databasekonfigurasjon beskriver en situasjon hvor to identiske instanser av samme database kjører samtidig. Database A er instansen som tar imot trafikk og persisterer endringer, hvor de påvirkede radene enten synkront eller asynkront replikeres til Database B. Dermed finnes det en backup som alltid er oppdatert med nyeste data, og klar til å motta trafikk på kort varsel dersom det skulle bli behov for det.
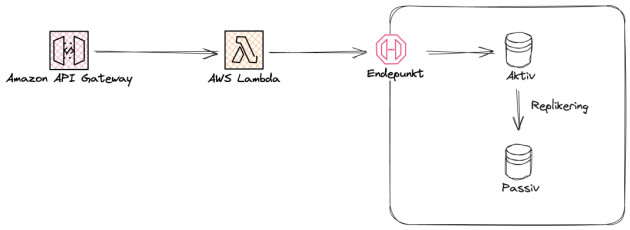
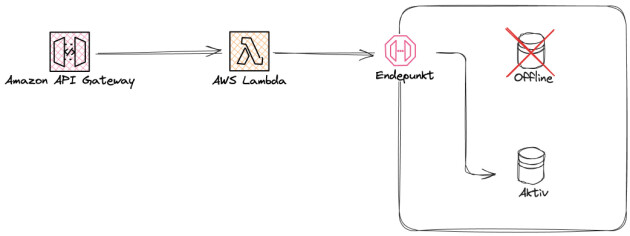
Om Database A går ned, har en vanligvis helsesjekker av databasen som oppdager dette raskt. Når dette oppdages, skifter systemet trafikken over til Database B automatisk. For sluttbruker vil forespørsler fremdeles bli gjennomført, og tidligere persistert data vil være tilgjengelig. På utsiden fremstår det i teorien som om ingenting har skjedd, men i praksis kan det være et svært kort vindu med nedetid før det plukkes opp at Database A er nede og trafikken skiftes til Database B. På denne måten sørger en aktiv-passiv databasekonfigurasjon for redundans og sømløs feilhåndtering.
De negative sidene med denne konfigurasjonen er åpenbare; én av to instanser er en passiv deltager, og gjør ikke noe faktisk arbeid før primærdatabasen tar kvelden. Skalering blir også et problem, ettersom oppsettet i utgangspunktet kun muliggjør vertikal skalering av databaseinstanser.
En kan delvis komme seg rundt skaleringsproblemet ved å opprette én database per region, og basert på brukerens lokalitet sende dem til den nærmeste tilgjengelige databaseinstansen. For å få til dette vil en måtte sette opp et komplekst synkroniseringssystem for å opprettholde datakonsistens, i tillegg til at hver nyopprettede databaseinstans må ha sin egen passive backup. Dette blir fort grisete, og lite fristende å vedlikeholde selv. Heldigvis finnes det tilbydere som AWS som kan gjøre grovarbeidet. Dette skal vi se nærmere på hvordan DSQL løser for oss.
I en Aktiv-Aktiv databasekonfigurasjon tar både Database A og Database B imot trafikk, ofte med en lastbalanserer foran. Innkommende trafikk blir fordelt mellom databasene i clusteret som fører til jevnere last, økt gjennomstrømning av data og (i teorien) “uendelig” skalerbarhet.
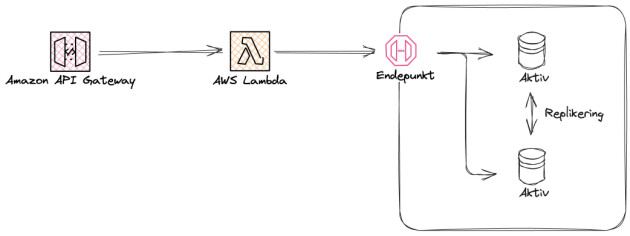
Aurora DSQL tar aktiv-aktiv-konseptet flere skritt videre enn tradisjonelle implementasjoner. I stedet for å ha to eller flere separate databaser som må holdes synkroniserte, bygger DSQL på en oppdelt arkitektur hvor selve databasen er designet fra grunnen av for å håndtere samtidige lese- og skriveoperasjoner fra flere geografiske lokasjoner. Dette er gjort ved å skille prosesseringslaget fra datalagringen, som ofte er tett sammenknyttet i tradisjonelle databasearkitekturer.
Den mest interessante forskjellen ligger i hvordan DSQL håndterer transaksjoner. Når en applikasjon sender en skriveoperasjon til hvilken som helst DSQL-instans, committes ikke transaksjonen lokalt før den replikeres til andre instanser i clusteret. I stedet benytter DSQL en distribuert transaksjonslogg som sikrer at alle skrivinger blir propagert til alle instanser før de bekreftes som vellykkede. Dette skjer synkront, noe som garanterer at alle noder til enhver tid har en konsistent versjon av dataen.
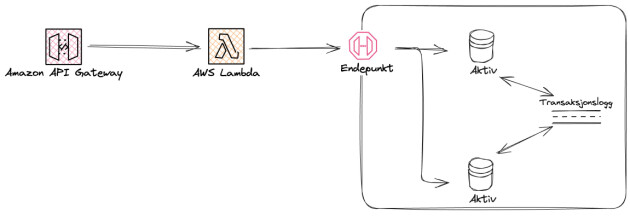
For å oppnå dette uten å ofre nevneverdig ytelse, implementerer DSQL det de kaller optimistic concurrency control (OCC). I motsetning til tradisjonelle databaser som låser rader eller tabeller underveis i transaksjonene, antar DSQL at konflikter mellom samtidige transaksjoner er sjeldne. Hver transaksjon utføres som om den er den eneste som kjører, og først ved commit-tidspunktet sjekkes det om transaksjonen kolliderer med andre samtidige endringer. Dersom det oppstår en konflikt, rulles den aktuelle transaksjonen tilbake og kan forsøkes på nytt.
Denne tilnærmingen gjør det mulig for DSQL å opprettholde sterke ACID-garantier selv når transaksjoner utføres parallelt på tvers av regioner og kontinenter. Det som tidligere krevde komplekse replikeringsstrategier og kompromisser innen datakonsistens løses nå transparent av plattformen selv. Utviklere kan fokusere på applikasjonslogikk fremfor å bekymre seg for hvordan data holdes konsistent på tvers av geografiske regioner.

#2: Snapshot Isolation
Snapshot-isolering er ett av flere mulige isoleringsnivåer databasesystemer kan legge seg på. Fra sterkest til svakest er rangeringen slik:
Serializable
Repeatable read (Snapshot isolation)
Read Committed
Read Uncommitted
Vi går ikke i dybden på alle isoleringsnivåene her, da Cockroach Labs’ artikkel "No Dirty Reads; Everything you always wanted to know about SQL isolation levels (but were too afraid to ask)" forklarer det veldig bra.
Den mest fremtredende svakheten ved bruk av snapshot-isolering, kalt write skew, blir eksplisitt håndtert av DSQL om utvikleren benytter seg av SELECT FOR UPDATE-keywordet. Denne kommandoen flagger leseraden for samtidighetskontroll utover det som vanligvis sjekkes via OCC, og unngår dermed problemet. Denne håndteringen innebærer at en som utvikler må ta høyde for at skrivetransaksjoner kan feile.
En flytter dermed noe av ansvaret for isolering og prøv-på-nytt logikken over på utvikleren, som må designe koden sin slik at transaksjoner automatisk blir gjenprøvd med en strategi for å sørge at sannsynligheten for at samme feil oppstår igjen blir minimal. Dette innebærer ofte et gitt antall prøv-på-nytt-forsøk med eksponentiell ventetid mellom forsøkene, ilagt et tilfeldig intervall ekstra pause for å sørge for at ikke alle transaksjoner prøver på nytt samtidig.

Den kloke leseren kan resonnere seg frem til at denne strategien hvor en ruller tilbake mange transaksjoner etter å ha blitt nesten utført raskt kan føre til trøbbel. Dersom det er et sett med rader som ofte skrives til vil det oppstå problemer ved at en stor andel av transaksjonene rulles tilbake og bruker dyrebar tid på nye forsøk som heller kunne vært løst ved bruk av pessimistisk låsing (PCC). Dette er en kjent svakhet ved OCC og DSQL er intet unntak. Utvikleren må selv være klar over dette, og designe applikasjonslogikken sin til å forsøke å holde transaksjoner korte og ikke låse for mye på en gang.
Dette kan i noen tilfeller være vanskelig i praksis, og da må en heller falle tilbake på flere forsøk med ventetid for å få gjennomført transaksjonen sin.
Fordeler ved Aurora DSQL
DSQL gir deg mye ut av boksen, og kan være verdt å ta en titt på dersom ditt team har et eller flere av følgende behov:
- Du ønsker en PostgreSQL-kompatibel SQL-database: Aurora DSQL er kompatibelt med PostgreSQL-APIet, som tilbyr en god utvikleropplevelse med mange triks og snarveier som sparer deg for kompliserte SQL-spørringer og innstillinger.
- Du har høye krav til tilgjengelighet og oppetid: Aurora DSQL garanterer 99.99% tilgjengelighet om du kjører et single-region cluster, og 99.999% tilgjengelighet om du kjører multi-region cluster. I løpet av en måned, tilsvarer dette maksimalt 4 minutter og 22 sekunder nedetid for et single-region cluster og 26 sekunder nedetid for et multi-region cluster.
- Du ønsker å ikke ha ansvaret for skalering og allokering av ressurser: Aurora DSQL er “serverless”, og krever følgelig ingen oppfølging av deg som utvikler for å skalere inn og ut clustered ditt i takt med bruk.
- Du forventer hyppig vekst: Aurora DSQL gjør det lekende lett å skalere opp kapasitet, på tvers av regioner og kontinenter. Sammen med fordelen en får av at DSQL er serverless trenger en ikke gjøre kompliserte beregninger av forventet vekst per region. DSQL håndterer skaleringen opp for deg, uten at en trenger å committe til store reserverte instanser i hver nye region.
- Du er kostnadsbevisst og i oppstartsfasen: Amazon Aurora DSQL passer ypperlig for bedrifter i oppstartsfasen, hvor kapasitetsbehov ikke alltid er kjent. Sammenlignet med provisjonert Amazon Aurora, vil det være adskillig billigere å benytte seg av DSQL.
Aurora DSQL gjør det lekende lett å skalere opp kapasitet, på tvers av regioner og kontinenter.
Nedsider ved Aurora DSQL
Det finnes likevel en del nedsider det er viktig at en er klar over før en hopper over på DSQL. Enkelte av dem vil mest sannsynlig være showstoppere på nåværende tidspunkt, men AWS jobber kontinuerlig med forbedringer, så selv om det blir et nei på nåværende tidspunkt kan det være greit å følge med fremover på ny funksjonalitet som blir lansert.
- Manglende støtte for JSONB: Selv om DSQL pryder seg med å være PostgrSQL-kompatibel er dette en sannhet med modifikasjoner. Full PostgreSQL-kompabilitet er ikke implementert, deriblant manglende støtte for datatypene JSON og JSONB. Dette er en stor begrensning for de som ønsker å benytte DSQL som dokumentdatabase, noe PostgreSQL normalt fungerer ypperlig til. JSONB-støtte er noe som forventes å komme etterhvert, men enn så lenge må en smøre seg med tålmodighet.
- Ingen fremmednøkler: DSQL har ikke støtte for fremmednøkler. Selv om databasen oppleves som én logisk database for både utvikler og brukere, gjør dens distribuerte struktur at det å opprettholde referanseintegritet gjennom fremmednøkler påvirker ytelsen uforholdsmessig mye. Støtte for fremmednøkler hadde også økt RTT betraktelig, og AWS har derfor valgt å ikke støtte det i første omgang, om noensinne.
- Kun 10 000 rader av gangen: DSQL har en begrensning på oppdatering av mer enn 10 000 rader i samme transaksjon. Dette betyr at store datamigreringer eller oppdateringer av store tabeller må deles inn i flere oppdateringer, som øker kompleksiteten rundt slike operasjoner.
- Access tokens krever JDBC-oppsett: DSQL bruker AWS IAM, som igjen bruker tilgangsnøkler (access tokens) for databaseautentisering. Litt JDBC-oppsett er derfor nødvendig for å reautentisere lesende/skrivende tjenester før token går ut på dato. Dette fører til mer kompleks logikk for å håndtere en stabil forbindelse over tid.
- Overhead for utviklere: Som nevnt tidligere, må utviklere ta hensyn til at skriveoperasjoner kan feile, og at queries ikke blir for store. Mye av kompleksiteten som databaser ofte løser sømløst, er flyttet over på utvikleren. Det er i utgangspunktet ikke et problem dersom en ønsker å gå all-in på en databaseteknologi, men DSQL kommer samtidig med såpass mange begrensninger som gjør enkelte oppgaver upraktiske å benytte DSQL til.
Oppsummering
DSQL er en spennende ny database som gir oss flere nyttige garantier og ytelsesmønster vi ikke finner blant liknende teknologier.
Med PostgreSQL-kompabilitet og SQL som standard spørrespråk gjør den mye riktig, men det trekker dessverre ned at mye funksjonalitet vi forventer fra en relasjonsdatabase mangler og flytter mye kompleks logikk over på utvikleren.
Vår anbefaling er å sette seg godt inn i hvilke begrensninger DSQL har og hvordan det vil påvirke dine behov før en går for denne databasen.
Viktigst av alt burde en kanskje spørre seg selv: Trenger jeg egentlig en globalt distribuert database for å løse mine behov?

Videre lesning:
Marc Brooker, Visepresident og Distinguished Engineer hos AWS, har laget flere bloggposter om hvordan de bygde Amazon Aurora DSQL.
Lansering av DSQL på AWS re:Invent 2025: Re:Invent DAT420 - Deep dive into Amazon Aurora DSQL
Dokumentasjon om hvordan DSQL er bygget for parallellitet: Concurrency control in Amazon Aurora DSQL
Cockroach Labs har en knakende god artikkel om isolasjonsnivåer i en database: No Dirty Reads: Everything you always wanted to know about SQL isolation levels (but were too afraid to ask) - Cockroach Labs
Foretrekk oss i Google Discover
Ved å legge oss til som foretrukket kilde i Google vil du blant annet få opp flere av sakene våre i Google Discover. Tusen takk for støtten!































