
Plutselig klikka det for Johannas Copilot: - Hva skjedde her?
Johanna Jøsang forklarer hvordan grådige modeller, temperatur og tilfeldigheter styrer AI-en vår.

Publisert
GitHub Copilot er et nyttig verktøy når man skal generere tekst som kan utledes fra kodebasen man jobber i.
For en stund siden brukte jeg det for å skrive dokumentasjon for koden min, og da begynte den plutselig å produsere merkelig tekst:

Vanligvis lager verktøyet relativt godt skrevet dokumentasjon som krever lite retting, men denne gangen hadde den tatt fullstendig feil — den repeterte samme setning om og om igjen.
Hva var det som foregikk her?
Egen erfaring
Denne feilen minnet meg om en tekst-genereringsmodell jeg laget under min studietid. Denne hadde nemlig også endt i en løkke. Kunne dette være samme problem?
Modellene er begge tekst-generatorer som gir en score til kandidater for neste del i setningen, men det må nevnes at den jeg lagde var mye mindre avansert enn GitHub Copilot. GitHub Copilot er basert på GPT-3, som er en autoregressive språkmodell. En slik modell kan “forstå” (avhengig av din definisjon av ordet) og produsere tekst for naturlige språk.

Min modell, derimot, var en enkel LSTM som tok som input n antall bokstaver, og predikerte hvilken neste bokstav som var mest sannsynlig. Denne tekst-generatoren var trent på alle Sherlock Holmes bøkene, og produserte denne teksten:
“i am sure that you have been at the door and struggled and struck at the door of the stairs, and then he was a small part of the stairs, and then he was a small part of the stairs, and then he was…”
Denne setningen har ingen direkte skrivefeil, men mangler meningsfullt innhold, og språkmodellene vi bruker i dag er mye flinkere til å skrive innholdsrik tekst. Istedenfor å predikere neste bokstav så jobber slike modeller med større enheter, slik som ord eller deler av en setning. På denne måten kan en viss grad av semantiske sammenhengen mellom delene bli imitert i genereringsprosessen.
Her er det ingen repetisjon, så nå er vel alt bra? Ikke helt.
Trenger tilfeldigheter
Når en tekst-generator alltid velger det den har vurdert som best, kalles det for en “grådig” modell.
Ettersom output til denne modellen senere blir input når neste del av setningen skal genereres, så kan slike grådige modeller havne i endeløse løkker der samme tekst produseres om og om igjen.
For å forhindre dette er introduksjon av tilfeldighet løsningen. Jeg endret språkmodellen min fra å være grådig til å ta et tilfeldig valg vektet av scoren den hadde gitt hvert tegn. På denne måten var den mest sannsynlig til å velge det tegnet med høyest score, men ville ikke alltid gjøre det. Dette er et eksempel på noe den forbedrede modellen produserte:
“sherlock holmes in england the door, where the stairs, was wats, and went into the roof. i should not be someone connecte sharply, and he has not happon whethire i was at the sight of the matter about in the cellar, through the child which she happy that she was a supper and shugned heard an are the date. then, who was still of so side with an opinion, mr. holmes, at least”
Her er det ingen repetisjon, så nå er vel alt bra? Ikke helt.

Trenger temperatur
Dersom du leser teksten nøye så ser du med en gang at den fremdeles er lite meningsfull, men nå har skrivefeil også blitt introdusert. Disse oppstår fordi noen ganger er det bare ett tegn som naturlig blir neste i rekken.
For eksempel, på linje to så oppstår ordet “connecte”, som sannsynligvis skulle være “connected”. Men, ettersom modellen ikke lenger er grådig så ble bokstaven med høyest score ved en tilfeldighet ikke valgt. Derfor må enhver god språkmodell i en situasjon hvor det bare er en måte fortsette teksten på, velge denne.
Til dette problemet er temperatur-parameteren løsningen. Enkelt sagt, så bestemmer temperatur hvor grådig en tekst generator er.
Konseptet temperatur blir også utnyttet i andre områder innen maskinlæring der Softmax-funksjonen blir brukt for å lage en sannsynlighetsfordeling over valg, slik som i forsterkende læring. Når man legger til temperatur-variabelen i output funksjonen (Softmax) så kan man justere omfanget av forskjeller i sannsynlighetsfordelingen.
Dersom temperaturen øker, blir fordelingen mer lik. Teoretisk sett, ved uendelig høy temperatur, har alle valg lik sannsynlighet. Om temperaturen minker, blir forskjellene derimot mer ekstreme. Da økes høye sannsynligheter, og lave sannsynligheter minkes. Dette er ønskelig, ettersom man vil at modellen praktisk talt “aldri” velger noe som er sterkt uegnet som neste del i sekvensen.

Så, hvorfor repitisjon?
Likt som GitHub Copilot, er ChatGPT basert på GPT-3. Jeg har aldri opplevd den generere repetitiv tekst, slik som GitHub Copilot gjorde, så man kan spekulere om temperatur-variabelen er lavere i GitHub Copilot eller om det er noen andre mekanismer på plass for å forhindre at tekst-generatoren ikke havner i en løkke.
I motsetning til GitHub Copilot så svarer ChatGPT forskjellig på samme ledetekst (prøv dette selv!). Her er to eksempler på hvordan den svarer på spørsmålet: “What movie should I watch tonight?”:
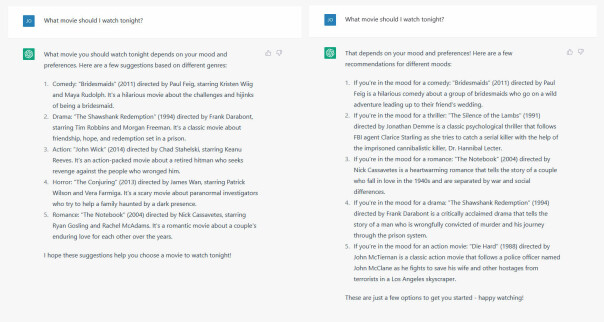
Jeg leste senere i dokumentasjonen til OpenAI at alle deres modeller er ikke-determinisktiske, og at selv om man setter temperaturen til null så kan det være noe variasjon i output.
Så, GitHub Copilot sin evne til å meningsløst repetere seg selv stammer fra kombinasjonen av at den velger den mest sannsynlige måten å fortsette teksten på og at den bruker sin egen output som input. Da ender den alltid opp med å generere samme setning om og om igjen, og det er lett å «prompte» språkmodellen til å havne i en slik løkke.
ChatGPT, på den andre siden, repeterer seg selv ikke lite lett og er kanskje litt mere kreativ i sine svar.
Om du syns ChatGPT er litt for kreativ, så kan du sette opp din egen modell gjennom OpenAI sitt API. Her kan du senke temperaturen og få et fokusert, om lite kreativt, svar på det du lurer på. Det kan hende at du får en litt repetitiv samtalepartner.
Foretrekk oss i Google Discover
Ved å legge oss til som foretrukket kilde i Google vil du blant annet få opp flere av sakene våre i Google Discover. Tusen takk for støtten!

































