DNB forberedte seg i åtte måneder på Disaster Recovery-øvelsen
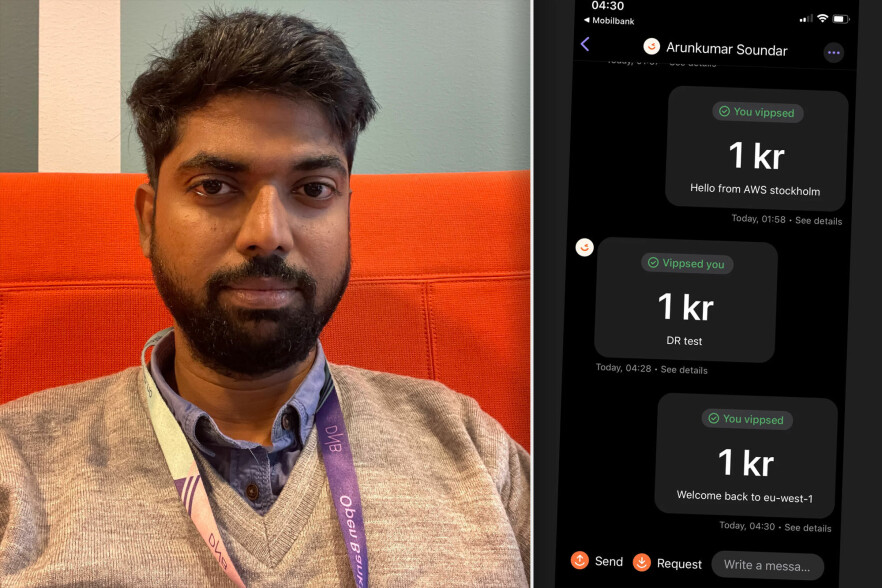
- For å sikre på at vi var 100 prosent fornøyd, overførte vi 1 krone via Vipps.

Publisert
Etter åtte måneder med koordinerte forberedelser utførte vi i OpenBanking og Business Continuity-teamene i DNB en Disaster Recovery (DR)-øvelse for våre PSD2 API-er.
Målet med øvelsen var å demonstrere at vi kan gjenopplive våre kritiske PSD2 API-er på fire timer, selv når det er en alvorlig skade eller utilgjengelighet i produksjonssystemet.
Vanligvis kjører våre PSD2 API-er fra AWS Europe (Irland)-regionen. Under DR-øvelsen derimot, flyttet vi hele arkitektruren til AWS Europe (Stockholm)-regionen og migrerte produksjonstrafikk til samme lokasjon.
Ved å bruke native AWS-skytjenester bygde vi den på serverløs arkitektur.
Stor jobb
DR-øvelsen er en obligatorisk compliance-aktivitet i henhold til bankforskrifter for en gruppekritisk tjeneste som PSD2.
Utgangspunktet for øvelsen vår var at kritiske tjenester som kjører i AWS Europe (Irland)-regionen sluttet å fungere.
Det betyr at vi måtte lage hele infrastrukturen i en backup-lokasjon, distribuere applikasjonskoden og deretter viderekoble produksjonstrafikken til backup-lokasjonen.
Standarden hos DNB for å utføre en slik operasjon er innen fire timer.

Flere veier til mål
For en slik hendelse er det flere måter å forberede seg på:
- En mulighet er å kjøre to kopier av systemene parallelt, og når en katastrofe inntreffer, bytter vi produksjonstrafikken til den som er upåvirket. Dette er imidlertid en kostbar løsning.
- Et annet alternativ er å ta sikkerhetskopi av dataene og hele systemet med jevne mellomrom og gjennoprette det når en katastrofe inntreffer. Dette alternativet er billigere, men utsatt for tap av data og lenger restaureringstid.
- Vi endte opp med en «Pilot light»-tilnærming som utnytter begge alternativene, og replikerer dataene og deler av arkitekturen på to steder kontinuerlig, men holder kun en liten del av infratstrukturen i gang i den sekundære lokasjonen.
Fra 4 timer, til 1 time, til 10 minutter
Under DR-øvelsen implementerte vi resten av arkitekturen, implementere applikasjonen, utførte automatiserte og manuelle tester, og ledet deretter produksjonstrafikken til det nye lokasjonen.
For å sikre at vi var 100 prosent fornøyd, overførte vi 1 krone via Vipps fra en konto til en annen. Og til hele teamets glede var det vellykket.
Gjennom denne øvelsen ønsket vi å holde produksjonstrafikken trygg og upåvirket i størst mulig grad. Dette gjorde øvelsen lenger enn hva vi kunne gjort i et virkelig katastrofescenario. Sammen med automatisert testing utførte vi også manuell ende-til-ende-testing, og ytelsestesting, før vi byttet trafikken til Stockholms-lokasjonen.
Inkludert alle disse aktivitetene tok det oss rundt én time å fullføre øvelsen. Men i et virkelig scenario kan vi være så raske som 10 minutter.

Foretrekk oss i Google Discover
Ved å legge oss til som foretrukket kilde i Google vil du blant annet få opp flere av sakene våre i Google Discover. Tusen takk for støtten!

































