
- Vi sitter på helt syke datamengder
Slik samler Nasjonalbiblioteket 1.000 gigabyte i timen fra norske nettsider. - Mange kan spore hele livet sitt i systemet.

Publisert
Vet du hvem Disney ringte da de skulle feire 75-års jubileum, og ikke klarte å finne igjen en gammel film?
Nasjonalbibliotekets lager i Mo i Rana, selvfølgelig!
I fire gigantiske fjellmagasin lagres rubbel og bit av historisk materiell. Er du fan av gamle VHS-filmer? Nasjonalbiblioteket har 700 paller av dem. Faktisk er de usikre på om det finnes nok VHS-spillere i verden til å digitalisere alt, og har tydd til Ebay allerede for å kjøpe opp gammelt utstyr.
Den kinesiske filmklassikeren Pan Si Dong fra 1927, som kineserne trodde gikk tapt under kulturrevolusjonen, den fant de jaggu igjen i Mo i Rana.
Foreløpig resulterer det i en innsamling på rundt 1.000 gigabyte i timen. Totalt 25 petabyte med digitalt innhold.
I postkassa til Nasjonalbiblioteket i Mo i Rana ramler det inn aviser fra hele Norge hver dag. Faktisk har alle aviser, tidsskrifter og andre trykte medier plikt til å sende inn syv eksemplarer, i det som kalles pliktavleverings-loven.
Materialet blir behørig strøket, hver side blir digitalisert i vanvittig oppløsning og alt blir lagret på disk i Mo i Rana. Hver eneste dag.
Men så var det nettet, da. Gjelder avleveringsplikt-loven der og? Og hva gjør Nasjonalbiblioteket med det?
Avleveringsplikt
- I 2016 kom det en revidert utgave av avleveringsplikt-loven, som tar for seg digitale medium, forteller teamleder i Nasjonalbiblioteket Thomas Langvann.
I Mo i Rana sitter han sammen med fire andre utviklere, og prøver å løse hvordan de skal få samlet inn alt som lagres av norsk digital informasjon på nettet.
- Bare av .no-domener er det vel rundt 820.000, men vi skal i utgangspunktet samle inn alt som står på norsk på nettet, og alt skal lagres med et tusenårs-perspektiv, forteller Langvann.
Foreløpig resulterer det i en innsamling på rundt 1.000 gigabyte i timen. Totalt 25 petabyte med digitalt innhold, fordelt på et disklager og et tape-lager.

Tusenvis av nettsider
Har du en blogg gående på nettet? Da kan det godt hende den befinner seg i Nasjonalbibliotekets arkiv, sammen med alt av bilder, video og andre filer som befinner seg på nettsiden din.
Nasjonalbiblioteket lagrer nemlig rubbel og bit, men foreløpig indekserer de ikke alle norske sider.
- Det er noen etiske spørsmål, forteller Langvann.
- Hva om vi høster inn bloggen til en 12-åring, som angrer og vil ha det slettet når hun er 17?

- Det er ikke alle steder som har noe avklart redaktøransvar, de sidene legger vi foreløpig ikke inn, konkretiserer Langvann.
Nasjonalbiblioteket har nemlig valgt å legge til nettsidene som blir indeksert manuelt. De fleste offentlige og store kjente nettsteder ligger riktignok inne; 230.886 sider for å være nøyaktig. Hver sjette time høstes en ny versjon av nettsidene i lista, med mulighet for å øke frekvensen ved store begivenheter.
- Den 22. juli oppdaget vi at forsidene til landets største aviser ble oppdatert svært ofte. Det tok vi konsekvensen av og økte frekvensen på forsideinnhøsting, slik at vi kunne dokumentere det på best måte, forteller Langvann.
Langvann forteller at de heller aldri sletter data, men klausulerer det som det er knyttet problemstillinger til.
- I forbindelse med ny pliktavleveringslov er det foreslått at man skal etablere en nemd som skal ta stilling til sletting og klausulering, omtrent som slettmeg.no, forteller Langvann.

Soper opp alt
For å få et brukelig snapshot av nettsider bruker Nasjonalbiblioteket hodeløs Chrome. Både et skjermbilde av nettsiden i desktop-modus og filene siden trenger for å fungere blir lagret.
- Det er en typisk man in the middle-fremgangsmåte, hvor vi inspiserer og lagrer all trafikk, forteller Langvann.

Ved hjelp av Chrome kravler de gjennom alle undersider og lagrer alt i en stor pakket fil i filmformatet WARC: Web Archive Format, en internasjonal standard for å arkivere websider, og en revidert utgave av Internet Archive sitt ARC-format.
Utvikleren Marius Elsfjordstrand Beck demonsterer at systemet de kaller Veidemann kjører 30 Chrome-instanser, fordelt på 20 høste-applikasjoner organisert med Kubernetes. Beck gjør oppmerksom på at tallene på antall instanser varierer.
Filene blir så lagret på et distribuert filsystem som kjører GlusterFS; et system Langvann forteller at fungerer greit, men har mye latency.
Det er genial funksjonalitet for utviklere.
Interessant databasevalg
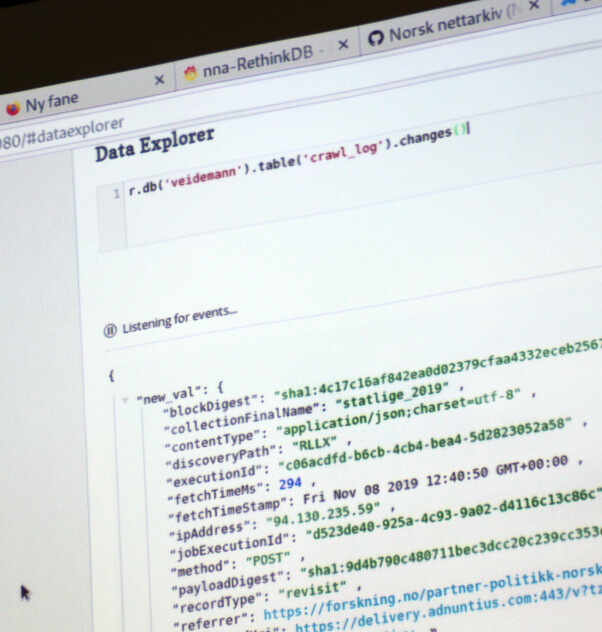
For å holde oversikt over alle instansene og hva som blir lagret, blir all loggdata pumpet inn i NoSQL-basen RethinkDB, som i utgangspunktet gikk konkurs i 2016. Heldigvis holdes den fortsatt i live av Linux Foundation.
Og selv om Langvann smiler når kode24s utsendte nevner Redis som alternativ, har Elsfjordstrand Beck en klar utviklerfordel å vise til:
I et vindu viser han nemlig oss RethinkDB sin utforsker, hvor man kan strømme forandringer basert på spørringer.
- Det er genial funksjonalitet for utviklere, men de har slitt litt med forretningsmodellen. Nå er de jo forøvrig på vei opp igjen, med sponsing gjennom Linux Foundation som vi også bidrar til, forteller Langvann.
Gammel traver i front
I frontend har Nasjonalbiblioteket standardisert på Angular, som de har brukt til å bygge grensesnittet for å legge inn og administrere nettsider.
Fra admin-grensesnittet har man full oversikt over hvilke nettsider som blir høstet, hvor ofte, og om filer som robots.txt skal respekteres.
Backend-språk varierer mellom Go og Java. Arkitekturen består av en rekke mikrotjenester, og utviklerne kan stort sett velge selv hvilket språk de foretrekker, ifølge Beck. Beskjeder utveksles via gRPC, som teamet har valgt over tradisjonelle REST-API-er.
- Det er et mer effektivt format, i forhold til JSON, som heter ProtoBuf og bruker HTTP2, forteller Langvann.

📸: Jan Inge Larsen / Nasjonalbiblioteket
Målfrid
Men hva all denne dataen brukes til, og hvem som skal få tilgang, det har ikke gjengen fokusert så mye på foreløpig.
- Vi har ikke gjort mye for å formidle dataen ennå, forteller Langvann.
- Vi sitter på helt syke datamengder, mange kan spore hele livet sitt i systemet vårt, forteller han og viser et søk på seg selv.
- Vi sitter på helt syke datamengder, mange kan spore hele livet sitt i systemet vårt
- Her ser man alt fra når jeg ble født, som ble skrevet om i lokalavisa, til saker fra arbeidslivet mitt.
Et internprosjekt gjengen selv bygger er en såkalt målforms-identifisering, som heter Målfrid. Ifølge målloven skal nemlig alle offentlig nettsider inneholde minst 25 prosent av hver målform, som betyr at 25 prosent av siden må være på nynorsk.
Noe som ikke er veldig lett å analysere, ifølge Langvann.
- En utfordring er å finne ut hva som faktisk er tekst på siden, og hva som bare er funksjonalitet. Målfrid finner menyer og dialogbokser, og de er ofte skrevet på bokmål, men skal de være med i beregningen? undrer Langvann.
Noen visning av nettarkivet har gjengen heller ikke gjort tilgjengelig foreløpig.
- Grunnet juridiske og etiske problemstillinger har vi foreløpig ingen visning av nettarkivet. Det er ikke enkelt å få tilgang som forsker heller, forteller Langvann.
Mer åpenhet
I fremtiden håper Langvann at Nasjonalbibliotekets internettarkiv skal kunne sope opp enda flere norske nettaviser. De eksperimenterer allerede med maskinlæring for å finne nettsider hvor det er skrevet på norsk.

Nettaviser som tilbyr artikler bak betalingsmur har de heller ingen løsning på plass for, enda Langvann påpeker at de plikter å tilgjengeliggjøre det for Nasjonalbiblioteket.
All kode gjengen bygger har de gjort tilgjengelig på Nasjonalbiblioteket sin Github-side for nettarkivet allerede, og all kode er open source.
Langvann håper de skal bli enda mer åpne i fremtiden.
- Dette skal lanseres som en åpen platform i en eller annen form, messer Langvann.
Så hvem vet, kanskje vi får en norsk variant av Internet Archives Wayback Machine i fremtiden? Da blir den i så fall tjent fra en fjellgruve i Mo i Rana.
Foretrekk oss i Google Discover
Ved å legge oss til som foretrukket kilde i Google vil du blant annet få opp flere av sakene våre i Google Discover. Tusen takk for støtten!


































