
The best way to learn deep learning
The basics of how Deep Neural Networks learn, by writing the core learning algorithms using only pure Python.

Publisert
After studying Deep Learning, I found out that the best way to learn is to first write every learning algorithm by hand along with understanding it without using any framework or library. This will allow you to easily and quickly learn modern deep learning libraries / frameworks like Keras and Tensorflow and truly understand what is happening. This method will give you the power to create better A.I systems.
The main goal of this series of articles is to write a program that will learn from images using no libraries or frameworks.
In this first part, we are going to dive into the important basics of how these Deep Neural Networks learn by writing the core learning algorithms on our own using only pure Python. We are going to create a simple program that will learn from basic data just to understand the basics of a neural network.

The plan
I will explain the core basics of a neural network in pure code.
We will write a small neural network in python that will learn using very simple data inputs without any framework or library.
What is a neuron?
A neuron in this context is simply a function that takes an input and produces an output. Having many neurons (functions) means that we take many inputs and produce many outputs inside a neuron.
How can a neuron learn in a neural network?
The neurons in the network take an input variable as information and uses a weight variable as knowledge and returns a prediction as output. All neural networks you’ll encounter will work like that. Weights are used as the knowledge to interpret the information in the data from input. Neural networks can and will take in bigger and far more complicated input and weight values, but the idea is the same as described here.
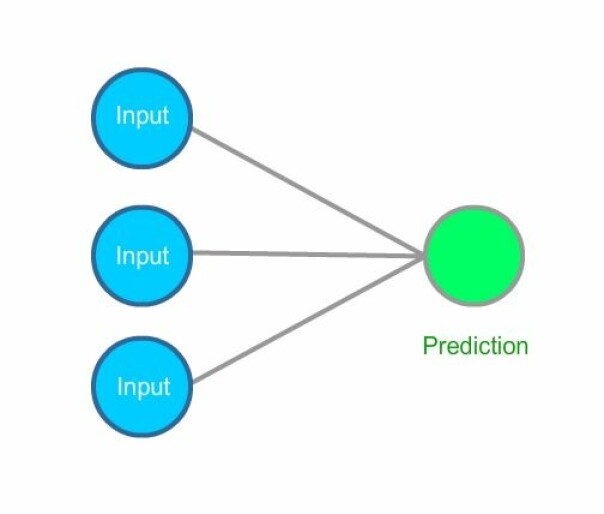
A collection of neurons that send data to each other are called a Neural Network. They have the power of multiplication.
One neuron takes an input datapoint (for example, 10.5) and multiplies it by the weight. If the weight is 2, then the neuron will double the input. If the weight is 0.01, then the neuron will divide the input by 100. Some weight values make the input bigger, and other values make it smaller to make the correct prediction.
Here’s an example of a Neural network with one neuron in code below:

The neural network learns through every step it takes. It starts by trying to make a prediction. Then, it sees if the prediction was too high or too low. It then changes the weight (up or down) to predict more accurately the next time it sees the same input. We will see how to change the weight so that we can predict correctly by moving the weight value up or down depending on the input and the wanted prediction. This is how a neuron network learns.
This is how a neuron network learns.
What we just did is called forward propagation. We are moving from the input and forward propagating the value to a prediction that we will pass forward to the next layer in the network.
Does our network predict correctly?
To allow our network to predict correctly, we have to somehow measure the error between what the network predicted and what we want it to predict correctly so we can adjust the values and move it in the correct direction. Measuring error is a way to see how much we missed. There are many ways to calculate error. This one is called a mean squared error function. It can be illustrated and coded like so:
Goal Prediction Variable
Like input, goal_prediction is a number you recorded in the real world. Sometimes it is something hard to observe, like “the percentage of people who did wear winter jacket,” given the temperature; or “whether the football player did score a goal in a penalty,” given his scoring average.
Why is our error squared?
The reason to square “how much you missed” which we call an error is that it forces the output to be positive. (pred - goal_pred) alone could be negative in some situations, unlike actual error. We want a positive error value we can work with, that allow us to measure how much we missed.

Why do we need to measure error at all?
The goal of training a neural network is to make correct predictions. You want your network to take an input that you can easily calculate (today’s electricity price) and predict things that are hard to calculate (tomorrow’s electricity price). That’s what makes a neural network very useful.
Changing the weight variable to make the network predict the right goal_prediction is a little bit more complicated than changing weight to make error == 0. Trying to get the error to 0 is more straightforward.
How do we learn?
Learning is really about one thing: adjusting the weight variable either up or down so the error is reduced. If you keep doing this and the error goes to 0, you’re done learning!
How do you know which way to turn the weight variable up or down?
You simply modify the weight to reduce error.
weight, goal_prediction, input = (0.1, 0.7, 0.3)
for iteration in range(13):
pred = input * weight
error = (pred - goal_prediction) ** 2
delta = pred - goal_prediction
weight_delta = delta * input
alpha = 3
weight -= weight_delta * alpha
print("Error:" + str(error) + " Prediction:" + str(pred))Delta is a measurement of how much this node missed in our neural network (a diff). For example, let’s say that the true prediction is 1.0, and the network’s prediction was 0.85, so the network was too low by 0.15. Thus, delta is negative 0.15. It’s the raw number or value that indicates that the node was too high or too low.
weight_delta is a number or value of how much a weight caused the network to miss. This value will help us see and reduce how much we have missed so we can predict accurately for each iteration.
You can calculate it by multiplying delta by the weight’s input. This will allow you to create each weight_delta by scaling its output node by the weight’s input. This fulfills 3 aforementioned attributes of direction and amount which are: scaling, stopping, negative and reversal.
Finally, you multiply weight_delta by a small number alpha before using it to update weight. This allows you to have control on how fast the network learns. If it learns extremely fast, it can update weights very aggressively and overshoot the prediction right off. Move slowly and predict very accurately down to zero error. :)
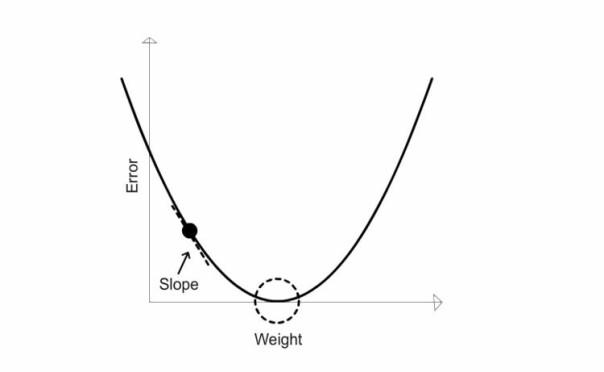
The slope seen in the above image points us to the bottom of the bowl, which is the lowest error number in the function no matter where you are in the bowl. We usually use these type of slopes to help our neural network reduce the learning error value and find the weight based on the lowest error number.
The top secret equation
For any input and goal_prediction, a very good relationship is made between error and weight, found by combining the prediction and error formulas. Take a look:
error = ((input * weight) - goal_prediction) ** 2The learning model
Changing the weight means the function conforms to the patterns in the data. We are forcing the rest of the function to be unchanging. You simply try to force the function to correctly model some pattern in the data. It’s only allowed to modify how the network predicts.
What’s next? A Deeper Neural Network
You can now easily create many neurons that can take vast amount of inputs and make predictions in various ways. Our work is not done yet. The example shown here is a very simple neural network that does not have any hidden layers. We will dive into Image Recognition using Convolutional neural nets without any deep learning frameworks or libraries in my next article.
Happy Coding.
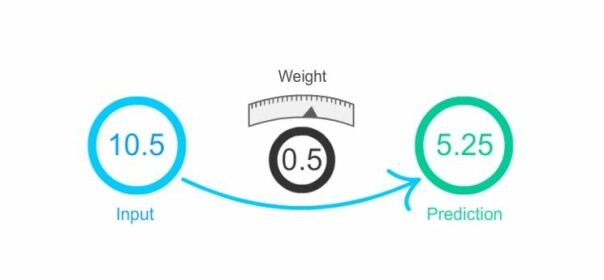

weight = 0.5
input = 10.5
goal_prediction = 7
prediction = input * weight
error = (prediction - goal_prediction) ** 2
print(error)
def simple_neural_network(input, weight):
prediction = input * weight
return prediction
Foretrekk oss i Google Discover
Ved å legge oss til som foretrukket kilde i Google vil du blant annet få opp flere av sakene våre i Google Discover. Tusen takk for støtten!



































