
Sånn veit Ruter-appen hvor mange folk det er på bussen du skal ta i morgen
Enorme mengder data, mye vasking, maskinlæring og nøye overvåkning gjør at du skal vite om du får plass til barnevogna på bussen.

Publisert
- En bruker som venter på en holdeplass med barnevogn, vil gjerne vite om det vil være nok plass til ham eller henne i bussen når den kommer, sier Jawad Saleemi og Mirjam Snåre Jarbo til kode24.
De er henholdsvis "AI lead" og produkteier i Ruter, og jobber blant annet med Ruter-appen.
En app som nå nettopp kan fortelle de reisende hvor full bussen eller trikken i Oslo-området trolig kommer til å være, opptil tre dager før turen skjer.
- Det har vært stor interesse fra Ruters kunder for å kunne se dette, sier Saleemi og Jarbo.
Og nå har de fått det til, med masse, masse data - og en dæsj AI.
Sensorer i dørene
- Kjøretøyene er utstyrt med sensorer som rapporterer data om reisen i sanntid. Dette inkluderer passasjerer som går av og på ved hver holdeplass eller stasjon, plasseringen av kjøretøyet, innendørs- og utendørstemperatur, hastighet, kjørt distanse - i noen tilfeller rapporterer de til og med hastigheten på vindusviskerne, forteller Saleemi og Jarbo.
Å vise app-brukerne hvor mange passasjerer det faktisk er på en buss der og da, er med andre ord enkelt. Men her snakker vi altså om en spådom av antall passasjerer i framtida.
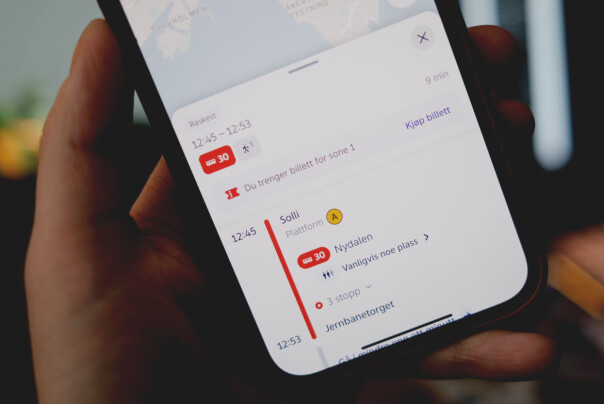
- For dette har vi brukt historisk data fra sensorene som rapporterer antall passasjerer ombord, forteller Ruter.
Det er noe så gammeldags som sensorer på toppen av hver dør som faktisk teller hvor mange som faktisk går inn og ut av bussen eller trikken.
- Disse dataene samles deretter inn av Ruters backend-systemer, og gjøres tilgjengelig for andre team for operasjonell og analytisk bruk.

Vaske, vaske, vaske
Alle som har jobba med store mengder data, veit at det er én jobb man må gjøre før man kan bruke dataen til noe: Vasking.
- Det er mye prosessering, rensing og datavalidering som pågår før dataene er gode nok slik at maskinlærings-modellene våre kan lære av dem, og produsere prediksjoner og innsikt, sier Saleemi og Jarbo.
Så Ruter må først behandle, rense og slå sammen data med andre interne datakilder for å både få egnede data og data i riktig kontekst.
- Men de er fortsatt ikke klare til bruk, fortsetter Ruter-utviklerne.
Først må de sikre kvaliteten på dem, gjennom en rekke kvalitetstester og kriterier, som skal være basert på "dataprofil og forretningsregler" fra Ruters domeneeksperter.
- Data som ikke blir godkjent av disse kvalitetstestene, erstattes av AI-genererte imputerte data, basert på historiske data. Til slutt blir "service-level"-dataene gjort tilgjengelige for virksomheten, for BI, analyser og AI-bruk.
Dette var spesielt kritisk under pandemien, siden vi kom inn og ut av lock-down, og vi ville fange opp disse mønstrene så snart som mulig.
To måneder, to modeller
Ruter bruker data fra de foregående to månedene til å lage predikasjoner for de neste tre dagene.
Å bare bruke de siste to månedene skal det være to grunner til:
- For det første, på grunn av pandemien, hadde vi ikke en god mengde stabile data siden reisemønsteret ble dramatisk påvirket under covid-19, forteller Saleemi og Jarbo.
- For det andre, ønsker vi å fange opp skiftende reisetrender så raskt som mulig. Dette var spesielt kritisk under pandemien, siden vi kom inn og ut av lock-down, og vi ville fange opp disse mønstrene så snart som mulig.
I tillegg til å måtte håndtere raske endringer i folks reisevaner, må de også håndtere forskjellige typer busser og trikker, med forskjellige antall plasser. Det er nemlig ikke sånn at de samme kjøretøyene alltid kjører den samme ruta. Dermed har Ruter også en egen modell for å forutse dette.
- Ved å kombinere disse to modellene, passasjertall og kjøretøytype, er vi i stand til å produsere predikerte fyllingsgrad, forklarer Ruter.

XGBoost og Kafka
Så er det bare å la AI-modellene kverne i vei:
Hva slags kjøretøy kommer ruta til å få tildelt, hvor mange passasjerer kommer trolig til å være inne i kjøretøyet til ett hvert tidspunkt, og hva slags "fyllingsgrad" vil dette utgjøre, som brukeren skal få se i appen sin?
- Det er mange teknologier involvert, forteller Saleemi.
- Språket det går i er, som det så ofte er i denne verdenen, Python.
- For treningen av modellene bruker de open source-biblioteket XGBoost (eXtreme Gradient Boosting).
- Infrastrukturen rundt skal i stor grad kjøre på diverse AWS-tjenester.
- Datadeling og -levering tar Apache Kafka seg av, med en ksqlDB-database.
- Hver dag gjør vi mellom seks og sju millioner predikasjoner, forteller Saleemi.
91 prosent nøyaktig
For at maskiner skal lære, må de vite om de tar feil eller ikke. Og Ruter følger nøye med.
Utviklerne har laga egne dash-bord som viser dem hvor godt predikasjonene treffer, ved å sammenligne dem med den faktiske sanntidsdataen som rapporteres.
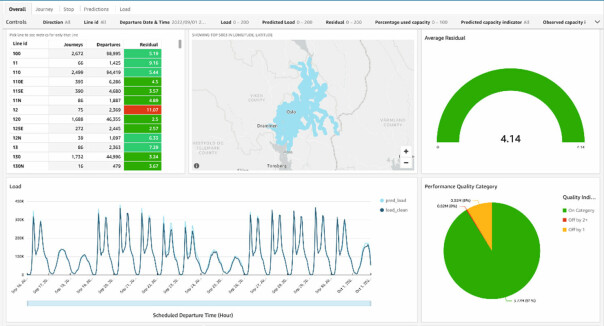
- Vi har også definert metrikker for å kvantifisere kvaliteten, forteller Saleemi og Jarbo.
De opererer med nøyaktige, seminøyaktige og unøyaktige predikasjoner. Ifølge Ruter skal modellene deres gi 91 prosent nøyaktige, 8 til 9 prosent seminøyaktige og mindre enn 1 prosent unøyaktige predikasjoner.

Veien videre
- Systemet fungerer som det skal, slår Saleemi og Jarbo i Ruter fast.
Før de rulla ut funksjonen testa de den lenge, både ved å se på rene tall, men også ved å faktisk gå ut i rush-trafikken og observere.
Nå får de også tilbakemeldinger gjennom appen fra brukerne, på hvorvidt AI-modellene fungerer som de skal. Nesten 20 prosent av tilbakemeldingene sier at predikasjonen var unøyaktig.
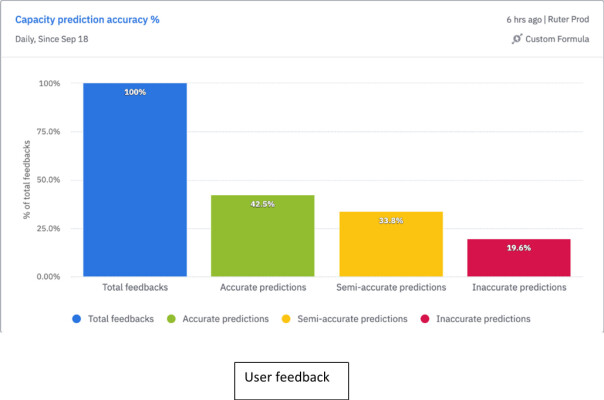
- Disse resultatene er veldig gode, tatt i betraktning det faktum at tilbakemeldingsdata fra kunder i slike tilfeller normalt er partiske mot negative tilbakemeldinger, siden det er mer sannsynlig å sende tilbakemeldinger når brukere er misfornøyde, forklarer Saleemi og Jarbo.
Og tilbakemeldingene tar de med seg videre - for jobben med AI-modellene er langt fra ferdig.
- Basert på tilbakemeldingene vi får fra brukerne våre, kan vi justere AI-modellene for å yte bedre for avgangene og rutene der brukerne har rapportert problemer. Samtidig jobber vi med å inkludere sanntidsdata i AI-modellene, noe som vil forbedre maskinlæringsmodellene drastisk.

Foretrekk oss i Google Discover
Ved å legge oss til som foretrukket kilde i Google vil du blant annet få opp flere av sakene våre i Google Discover. Tusen takk for støtten!

































