Googles Gemini 1.5 Pro skal danke ut OpenAI: «Overraska alle!»
Med 1 million "tokens" kan Gemini 1.5 Pro se på mye mer informasjon av gangen for å gi deg bedre svar.

Publisert
Google lanserte torsdag kveld norsk tid versjon 1.5 av sin store Gemini Pro-modell for tekst, bilde og lyd. I seg selv kanskje ikke så spennende, det går jo nesten ikke en dag uten at det kommer nye AI-lanseringer fra Google, OpenAI, Meta og andre.
Gemini 1.5 Pro er imidlertid en temmelig stor oppdatering som er verdt å få med seg.

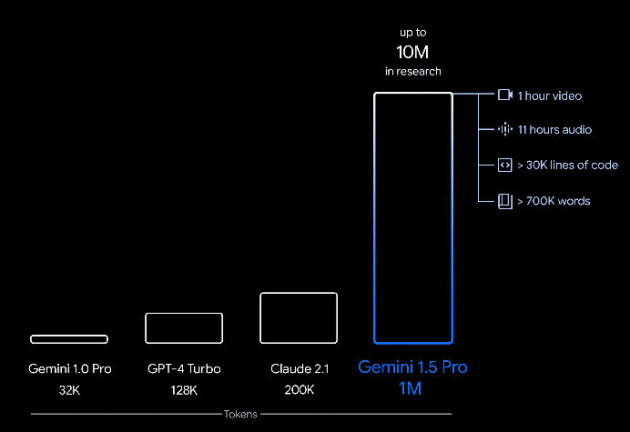
Med Gemini 1.5 Pro er nemlig kontekstvinduet til modellen økt betydelig, fra 32.000 tokens i dagens Gemini-modell til hele 1 million tokens i 1.5 Pro. Til sammenligning har OpenAIs GPT-4 128.000 tokens.
I praksis betyr det at Gemini 1.5 Pro kan se på mye mer informasjon samtidig når den skal svare på spørsmålene dine.
Større kontekst gjør den mer hjelpsom
Google forklarer at AI-modellens kontekstvindu utgjøres av tokens, som er byggeklossene som brukes for å prosessere informasjon. Et token kan være hele eller deler av ord, bilder, videoer, lyd eller kode. Er kontekstvinduet større, kan modellen ta inn mer informasjon av gangen for prosessering, i én enkelt "prompt".
Det skal gi mer konsistente, relevante og nyttige svar tilbake. Med 1 million tokens kan 1.5 Pro håndtere så mye informasjon samtidig:
- 1 time video
- 11 timer lyd
- Kodebaser med mer enn 30.000 linjer kode og 700.000 ord
Det stopper imidlertid ikke der: Google skriver at de allerede har testet med opptil 10 millioner tokens.
Bruker mindre ressurser
Ifølge Google er Gemini 1.5 Pro like bra som Googles toppmodell Gemini 1.0 Ultra. Men ved å ta i bruk en arkitektur som kalles MoE (Mixture-of-Experts) kan modellen gi svar som er på høyde med 1.0 Ultra og likevel bruke mindre CPU-ressurser.
Kort fortalt fungerer MoE ved å dele inn i mange mindre nevrale "ekspert"-nettverk, i stedet for ett stort nevralt nettverk. Når du spør modellen om noe, vil MoE-modellen avhengig av hva slags input den får aktivere bare de mest relevante delene av det nevrale nettverket. Dermed går alt raskere, og energiforbruket blir mindre.
– Våre nyeste innovasjoner i modellarkitektur gjør det mulig for Gemini 1.5 å lære komplekse oppgaver raskere og opprettholde kvaliteten, samtidig som den mer effektivt lar seg trene, skriver Google.

TheAIGRID har laget en gjennomgang av Gemini 1.5 og sett på hvordan den klarer seg mot konkurrentene, og virker overbevist:
– Google overrasket alle! Og nøyaktigheten er oppsiktsvekkende!
Se videoen her:
Foretrekk oss i Google Discover
Ved å legge oss til som foretrukket kilde i Google vil du blant annet få opp flere av sakene våre i Google Discover. Tusen takk for støtten!




























