
GitHub nede 13 ganger på 3 måneder: – Ikke akseptabelt
Slik skal GitHub unngå at det skjer igjen.

Publisert
GitHub opplevde nedetid tre ganger forrige uke, og i løpet av de siste tre månedene har tjenesten opplevd ulike former for avbrudd hele 13 ganger. Det skriver InfoWorld.
– Dette er ikke akseptabelt, og heller ikke standarden vi ønsker å holde oss på, skriver GitHubs Mike Hanley i et blogginnlegg.
Ingen sammenheng
Hanley skriver i blogginnlegget at de forrige uke – altså uken som begynte 8. mai – oppelvde flere "hendelser", både langvarige og korte. Disse har blitt rettet opp i, slik at alle systemer nå skal kjøre som normalt.
Vi tok umiddelbart grep for å bøte på sitasjonen.
Det som forårsaket hendelsene skal ikke ha hatt noe med hverandre å gjøre, men det førte uansett til ustabilitet og nedetid for GitHubs brukere.
– Vi tok umiddelbart grep for å bøte på sitasjonen, skriver Haley.

Konfigurasjonsfeil
Tre hendelser som skjedde 9., 10. og 11. mai, berørte flesteparten av kritiske tjenester fra GitHub, opplyser selskapet.
Den 9. mai gikk åtte av ti tjenester på GitHubs status-side ned, og var nede i over en time. I løpet av den timen kunne flere av GitHubs tjenester ikke lese ferske Git-data, noe som førte til en rekke feil. Det førte også til problemer etter at tjenestene kom opp igjen, da de nyeste pull request- og push-dataene måtte gjenopprettes.
Feilen skyldtes en konfigurasjonsendring i en intern tjeneste som leverer Git-data. GitHub forsøkte å rulle tilbake konfigurasjonsendringen, men dette gikk galt på grunn av en intern infrastrukturfeil.
Databasetrøbbel
Den 10. mai gikk det galt igjen, og seks av ti tjenester på GitHub status-siden gikk ned.
Årsaken var at en databaseklynge som leverte GitHub App-auth-tokens plutselig opplevde en sjudobling i forsinkelse (latency) ved skriving. Dette kom ifølge GitHub av en "lite effektiv implementering" av et API for å håndtere GitHub App-tillatelser.
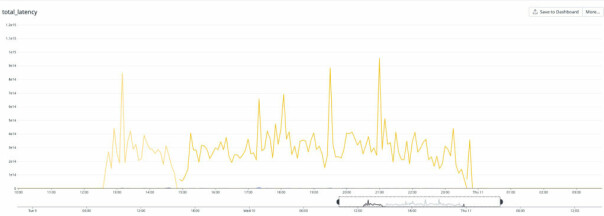
Allerede dagen etter var det igjen trøbbel og ustabilitet, da en databaseklynge som leverte git-data krasjet.

Går gjennom interne prosedyrer
Mike Hanley i GitHub skriver at de forventer at selskapets tjenester skal være så motstandsdyktige mot å gå ned som mulig. Selv om feil i et distribuert system er unngåelig så skal det ikke forårsake betydelig nedetid på tvers av flere ulike tjenester, skriver han.
Du kan lese flere detaljer om hva som gikk galt her.
Nå går GitHub igjennom interne prosesser for å sikre at endringer alltid rulles ut på en sikker måte i fremtiden.
Selskapet går også nøye gjennom følgene hendelsene fikk på tvers av ulike tjenester, slik at de kan redusere konsekvensene hvis noe lignende skulle skje igjen i fremtiden.
I tillegg jobber GitHub med løsninger for å bedre kunne diagnostisere og fikse feil raskt, samt sørge for at "failovers" fungerer som de skal når det er problemer med for eksempel en database.

Foretrekk oss i Google Discover
Ved å legge oss til som foretrukket kilde i Google vil du blant annet få opp flere av sakene våre i Google Discover. Tusen takk for støtten!






























