
Finnes leverte aksjelista i uleselig PDF – utviklere rydda opp med OCR og Python
Den 224 sider lange PDF-fila inneholdt ingen reell data, bare skjermdumper.

Publisert
Sent fredag ettermiddag i høstferien ga Erna Solbergs ektemann Sindre Finnes, gjennom advokatene sine, ut lista over alle aksjehandler han gjorde mens kona var statsminister.
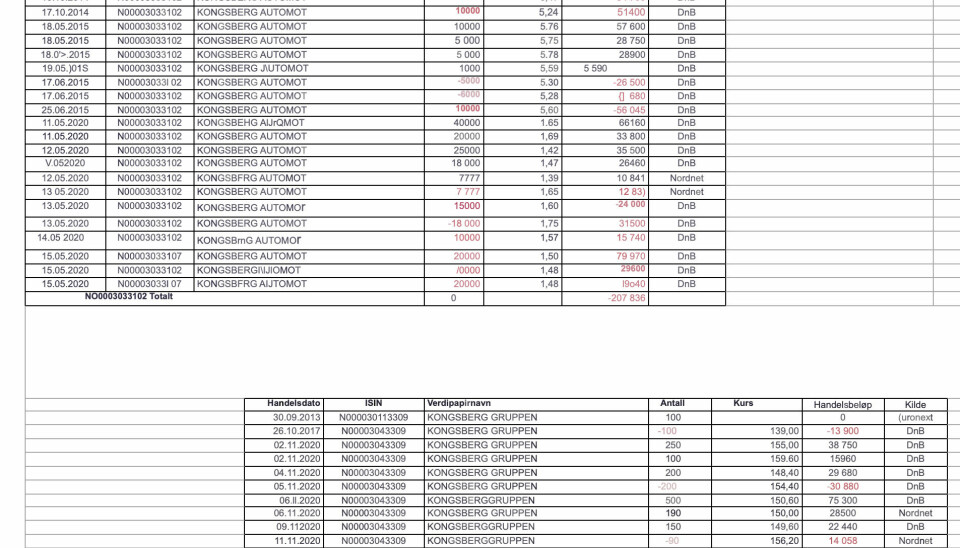
Lista bestod av skjermdumper fra et regneark, limt inn én og én på hvert sitt PowerPoint-lysbilde, som til slutt ble eksportert til en 224 sider lang PDF-fil.
Oversikten inneholdt altså bilder av data, ikke data i seg selv. Dermed var ikke aksjelista søkbar, og praktisk talt ubrukelig for både journalister og Stortinget som ville gå aksjehandlene nærmere etter i sømmene.
Både teknologer, jurister og politikere reagerte. Heldigvis har førstnevnte noen triks opp i ermet når det kommer til data, og blant annet E24 og VG har nå publisert en søkbar aksjeliste i Google Sheets.

"Ikke særlig gode"
- Vi hadde to hovedmål: Teksten skulle være søkbar, og innholdet skulle organiseres i et regneark, forteller redaksjonell utvikler Sondre Nilsen i VG til kode24.
De starta med å bruke Adobe Acrobats egne funksjon for optisk tegngjenkjenning, eller OCR som det kalles. Denne skal kunne ta bilder av tekst og gjøre det til faktisk tekst.
Videre prøvde de å eksportere denne teksten til et regneark.
- Men resultatene ble ikke særlig gode, sier Nilsen.
Maskinlæring med NanoNets
Veien gikk videre til NanoNets, som markedsfører seg med "Put your Business Processes on autopilot with AI". De tilbyr flere verktøy for maskinlæringsbasert behandling av data, blant annet en modell for tabellgjenkjenning.
- Med denne modellen produserte vi en CSV-fil som viste seg å være vesentlig bedre enn det Acrobat produserte, forteller VGs redaksjonelle utvikler.
- Det er verdt å nevne at det var den søkbare teksten fra Acrobat som ble lastet opp til NanoNets. Det er uvisst om dette ga noen fordel sammenlignet med å bruke det originale, ikke-søkbare dokumentet.

Oppvask med Python
Men CSV-fila var ikke perfekt. Blant annet så de raskt at det var unøyaktigheter i dataen, og problemer som doble mellomrom som tusen-skilletegn, og data som burde være rene tallverdier som ikke alltid var det.
I stedet for å igjen vende seg mot AI, bretta utviklerne opp ermene selv.
- Vi laget et Python-skript for å fjerne overflødige mellomrom, punktum og kommaer – både korrekte og feilaktige, sier Nilsen.
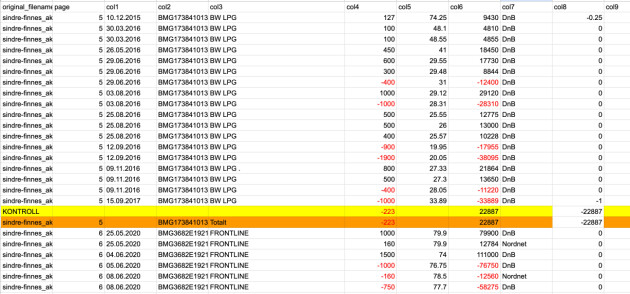
Etter denne vasken kjørte de CSV-fila inn i et regneark, for å se om de var i mål. Ved å blant annet sjekke totalsummer, som det opprinnelige dokumentet oppga for hvert av de 100 selskapene Finnes hadde kjøpt aksjer i, kunne utviklerne verifisere at tallene stemte. Dessuten kunne de sjekke at for eksempel antall aksjer ganger kursen stemte overens med kjøpssummer.
- Mesteparten av avvikene var relatert til manglende minustegn, avslutter Nilsen, og nå er regnearket altså publisert, med oppfordring til å si fra om leserne finner noen feil som har lurt seg unna.
Foretrekk oss i Google Discover
Ved å legge oss til som foretrukket kilde i Google vil du blant annet få opp flere av sakene våre i Google Discover. Tusen takk for støtten!































